#include
<iostream>
#include <cstring>
using namespace std;
int main(int argc, char *argv[])
{
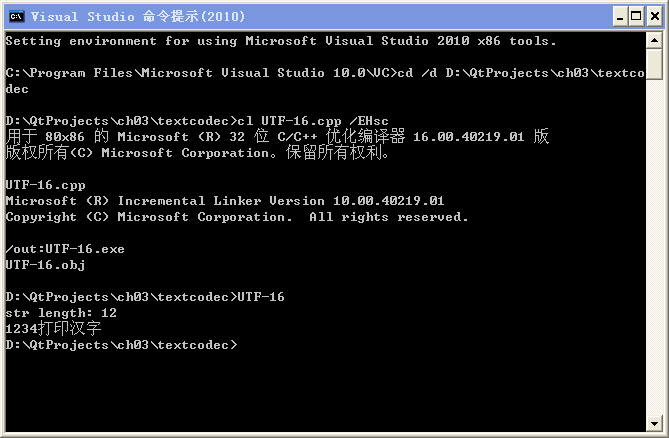
char theStr[] = "1234打印汉字";
cout<<"str length: "<<strlen(theStr)<<endl;
cout<<theStr;
return 0;
}
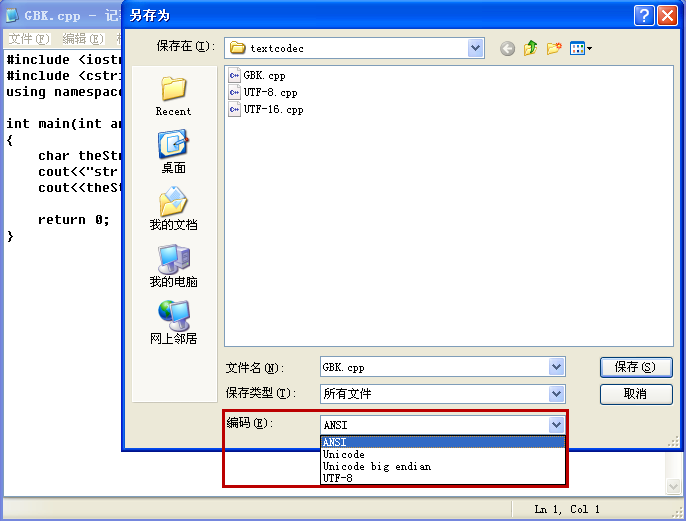
注意看文件存储的字节数:
 |
练习 |
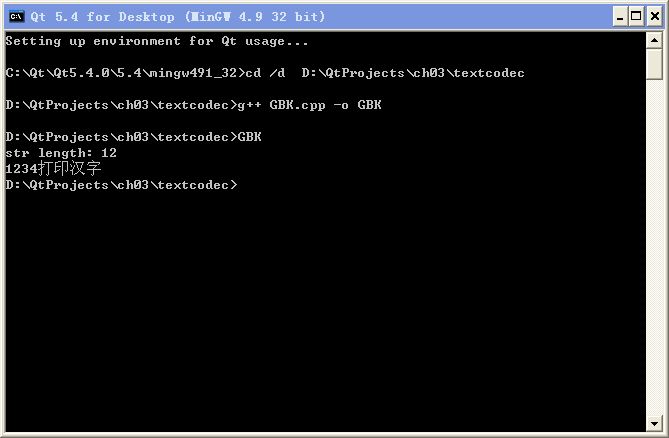
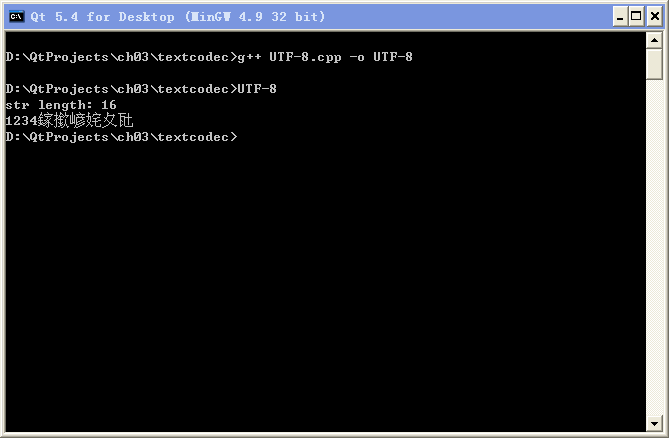
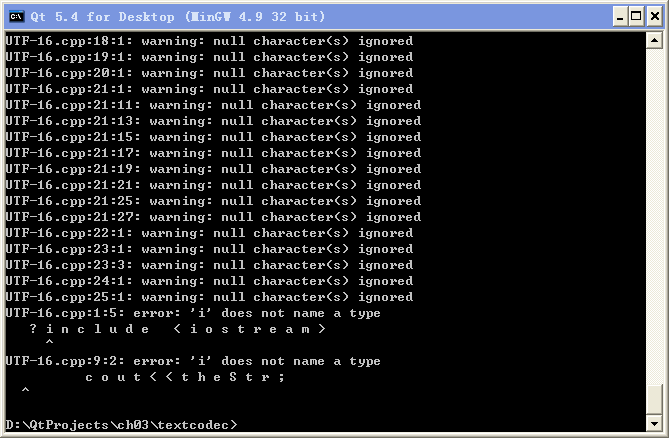
① 仔细查看本节用 g++ 编译生成的 GBK.exe、UTF-8.exe 和 MSVC 编译生成的 UTF-16.exe 打印显示的 str
length 数值,列出这三个数值的计算公式(与三个 cpp 文件长度计算公式对比看看)。
② 如果有 VS2010 SP1 以上的开发环境,在命令行编译本节三个源文件,然后可以用 VS 自带的 Microsoft Windows SDK
Tools 里的 WinDiff 工具对比 cl 编译器生成的 exe 文件,每次比较两个,看看二进制文件之间的差异。