3.4 使用 QByteArray
本节学习 QByteArray 的两种用法,第一种作为字符串处理类,类似 QString ,但 QByteArray
内部字符编码不确定,所以要慎用。第二种是作为纯的字节数组,里面可以包含多个 '\0' ,经常用于网络数据的接收和发送。本节示例代码下载地址在末尾小节
3.4.5 里。
3.4.1 QByteArray和char
Qt 最常用的字符串类是内码固定的 QString,而针对传统类似 C 语言 char* 的字符串,Qt 提供了 QByteArray
类来处理。QString 的字符单元是 QChar,QByteArray 的字节单元是 char。头文件 <QByteArray>
不仅自身以类的形式提供,它还针对传统 C 语言的字符串函数做了安全版本的封装,都加了 q 字母前缀,如
qstrlen、qstrncmp、qstrcpy,这些是全局函数,专门处理传统 C 语言的 char* 字符串,用法与 C
语言风格完全类似,比较简单,本节就不介绍了。本节主要介绍 QByteArray 类的使用。
QByteArray 类可以处理以 '\0' 结尾的传统字符串,包括 UTF-8 编码和其他如 GBK、Big5
等多字节编码的字符串,在作为字符串使用时,QByteArray
内部字符编码格式是不限定的,可以是任意编码的,所以程序员自己必须要事先确定程序会用到哪些编码的 QByteArray 。因为 Qt5 源文件规定是
UTF-8 编码的,所以 QByteArray 内部使用 UTF-8 编码的字符串居多。QByteArray
在赋值、传参数、返回值时也是使用隐式共享机制提高运行效率,只有字符串发生修改时才会执行深拷贝。
在文件处理、网络数据收发等场景,QByteArray 类是作为纯字节数组来使用的,里面可以包含任意数据,比如一堆
'\0',这时不要拿它当字符串看,它的存储长度与 qstrlen 计算的长度经常不一致。对于网络数据收发,QByteArray 经常配合
QDataStream 使用,对 Qt 数据类型做串行化(Serializing)。
3.4.2 QByteArray作为字符串使用
QByteArray 类作为字符串使用时,它会自动在字符串末尾添加 '\0' ,末尾的 '\0' 不计入字符串长度。QByteArray
字符串的内部编码是不固定的,比如前面 QString 的 toLocal8Bit 和 toUtf8 函数返回的对象全是 QByteArray
类型。QByteArray 字符串的数据来源可能有:
- ①源代码里的字符串,这时 QByteArray 内码与源文件的编码有关,UTF-8 编码源文件生成的很可能就是 UTF-8 编码的字符串。
- ②本地文本文件,从文件读取的字符串与该文件使用的字符编码有关,Linux 上常用 UTF-8,而 Windows 经常使用 ANSI
多字节编码,简体 Windows 系统一般是 GBK,而繁体默认是 Big5。
- ③网页数据,网页本身也是文本文件,有它自己的文本编码格式,这时网页文件编码格式决定 QByteArray 字符串的编码格式。
我们这里示范的是第一种,全部用 UTF-8 编码的 QByteArray 字符串。QByteArray 类关于字符串处理的成员函数基本和 QString
类的一样,函数名和参数都是类似的。但注意因为 QByteArray 内码不确定,它没有 arg 函数,也没有字符编码转换的函数。QByteArray
关于字符串处理的函数就不枚举了,和上一节 QString 的差不多,下面直接看示例代码:
void
TestStr() //内码 UTF-8
{
//数值与字符串转换
int nDec = 800;
QByteArray basDec;
basDec.setNum(nDec); //数值转字符串
qDebug()<<basDec;
QByteArray basReal = "125.78999";
double dblReal = basReal.toDouble(); //字符串转数值
qDebug()<<fixed<<dblReal;
//运算符
QByteArray basABCD = "ABCD";
QByteArray basXYZ = "XYZ";
qDebug()<<(basABCD < basXYZ); //二者字符编码一致才能比较!
qDebug()<<(basABCD == basXYZ);
qDebug()<<(basABCD >= basXYZ);
qDebug()<<(basABCD + basXYZ);
//子串处理
QByteArray basHanzi = "1234打印汉字";
//作为字符串时 QByteArray::length() 和 qstrlen() 一致
qDebug()<<basHanzi.length()<<"\t"<<qstrlen( basHanzi.data() );
//重复
QByteArray basMoreHanzi = basHanzi.repeated(2);
qDebug()<<basMoreHanzi.count("1234"); //统计次数
qDebug()<<basMoreHanzi.startsWith("1234"); //开头判断
qDebug()<<basMoreHanzi.endsWith("汉字"); //结尾判断
qDebug()<<basMoreHanzi.indexOf("1234"); //从左边查出现位置
qDebug()<<basMoreHanzi.lastIndexOf("1234"); //从右边查出现位置
//替换
basMoreHanzi.replace("1234", "一二三四");
qDebug()<<basMoreHanzi;
//切割字符串
QByteArray basComplexFile = " /home/user/somefile.txt \t\t ";
QByteArray basFileName = basComplexFile.trimmed(); //剔除两端空白
qDebug()<<basFileName;
//分隔得到新的 QByteArray 对象列表
QList<QByteArray> baList = basFileName.split('/');
//打印
for(int i=0; i<baList.length(); i++)
{
qDebug()<<i<<"\t"<<baList[i];
}
//没有段落函数
}
上面测试函数第一段是数值与字符串互相转换的,比较简单,打印结果是:
"800"
125.789990
浮点数转换时,定点计数法和科学计数法都是可以接受的,上面示范的是定点数。这些函数声明和功能都可以查阅 QByteArray 类的帮助文档。
第二段代码是运算符函数的,需要注意的是一定要在确定字符串内部字符编码的情况下,才能进行比较和拼接,上面用的全是 UTF-8
。不能将不同编码格式的字符串比较,因为得到的结果没意义,反而会造成误导。上面比较运算符的打印结果为:
true
false
false
"ABCDXYZ"
第三段是子串查询处理的,注意只有当 QByteArray 作为字符串处理时,它的 length() 函数计算的长度才会和全局函数 qstrlen()
计算的结果一致。子串部分打印的结果为:
16
16
2
true
true
0
16
"一二三四打印汉字一二三四打印汉字"
上面示范的 basMoreHanzi.replace("1234", "一二三四") ,这种形式的替换函数会对所有匹配的子串进行替换,它的声明是:
QByteArray & replace(const char *
before, const char * after)
如果要对指定位置的子串替换,需要换一个声明形式的 replace 函数,比如:
QByteArray & replace(int pos, int
len, const char * after)
这个函数会对指定位置 pos 开始的长度为 len 的子串进行替换,这个函数声明只做一次替换。
对于 replace 函数,必须注意字符编码的问题,UTF-8 的英文字符占用 1 字节,汉字通常是 3
字节,这种不确定性在替换函数和其他分隔子串函数时尤其需要注意,因为 3 字节的汉字如果被截断,就成错误的字符,造成信息损失。因此尽量不要用
QByteArray 类来处理字符串,尤其是涉及分割和替换的。QString 类的字符长度是固定的,所以最适合做字符串处理。
最后一段代码是子串分隔的,trimmed 函数功能也是去除两端的空白区域,split 函数将字符串分隔为多个子串之后按照
QList<QByteArray> 类型返回,QList 是一个模板类,QList<QByteArray> 就是存储多个
QByteArray 对象的列表,可以直接用中括号 [] 访问里面的各个对象。最后一段代码打印的结果如下:
"/home/user/somefile.txt"
0 ""
1 "home"
2 "user"
3 "somefile.txt"
分隔结果与上一节 QString 是一样的,对于开头 '/' 左边没有字符的情况,一样会分出来一个空字符串对象。因为一般用 QString
来处理文本字符串,QByteArray 类没有 section 函数,所以字符串处理时优先用 QString 类。
3.4.3 QByteArray作为字节数组使用
在读写文件、网络数据收发过程中经常将 QByteArray 作为缓冲区存储字节数据,这时候 QByteArray 就是纯的字节数组,里面可以包含任意个
'\0' 字节。下面以网络数据传输为例讲解,比如网络传输过程中既要传输数值类型 int、double,又要传输字符串类型 char*,对于普通的 C++
,最常用的是自定义一个结构体:
struct
NetData
{
int nVersion;
double dblValue;
char strName[256];
};
发数据时就将数值赋值给结构体对象的成员变量,字符串就用 strcpy
函数塞进去。这种方式可行,但缺乏灵活性,下次如果要传个不同的数据组合,就得重新定义。
Qt 对这类组合数据的打包方法就叫串行化(Serializing),在 Qt 帮助文档的索引里输入关键词 Serializing 就可以看到关于 Qt
串行化的帮助主题(Serializing Qt Data Types),除了 C++ 基本数值类型,Qt
还对大量自身的类对象做了串行化。串行化得到一个字节数组 QByteArray ,可以直接用于发送。Qt 串行化数据接收就是发送的逆过程,都是通过
QDataStream 流实现。下面简单示范一对函数,首先是串行化输出:
QByteArray
TestSerialOut()
{
//数据
int nVersion = 1;
double dblValue = 125.78999;
QString strName = QObject::tr("This an example.");
//字节数组保存结果
QByteArray baResult;
//串行化的流
QDataStream dsOut(&baResult, QIODevice::ReadWrite); //做输出,构造函数用指针
//设置Qt串行化版本
dsOut.setVersion(QDataStream::Qt_5_0);//使用Qt 5.0 版本流
//串行化输出
dsOut<<nVersion<<dblValue<<strName;
//显示长度
qDebug()<<baResult.length()<<"\t"<<qstrlen(baResult.data());
//返回对象
return baResult;
}
该函数里给定了三个数据:整数、浮点数和字符串对象,通过流 dsOut 将三个数据打包存到字节数组 baResult
里。对于串行化输出,QDataStream 的构造函数是以字节数组的指针和读写模式 QIODevice::ReadWrite 为参数,其构造函数声明为:
QDataStream(QByteArray * a, QIODevice::OpenMode mode)
然后设置串行化流的版本兼容,上面代码使用的是 Qt 5.0 版本的流格式;流格式设置好之后,就可以用 <<
将数据输出到流里面,QDataStream 类的函数会将数据打包好存到字节数组里面,最后返回这个字节数组对象就行了。
以字节数组方式使用的 QByteArray 对象,它的长度是不能用 qstrlen 之类的函数计算的,上面函数打印的结果如下:
48
0
字节数组实际占用 48 字节空间,而 qstrlen 函数计算的是 0,因为该字节数组第一个字节就是 '\0' 。
该函数返回的 baResult 就包含了三个要发送的数据,baResult 里面具体的数据格式不需要关心,收发两端 setVersion
的版本号一致就可以了。使用串行化就不再需要自定义结构体,所以用起来很方便。
网络收发过程到后面网络专题的学习再讲,现在仅学习一下串行化输出和输入的函数,baResult 数据的解析函数如下:
void
TestSerialIn(const QByteArray& baIn)
{
//输入流
QDataStream dsIn(baIn); //只读的流,构造函数用常量引用
//设置Qt串行化版本
dsIn.setVersion(QDataStream::Qt_5_0);//使用Qt 5.0 版本流
//变量
int nVersion;
double dblValue;
QString strName;
//串行化输入
dsIn>>nVersion>>dblValue>>strName;
//打印
qDebug()<<nVersion;
qDebug()<<fixed<<dblValue;
qDebug()<<strName;
}
对于输入流的构造,参数是常量引用,其声明如下:
QDataStream(const QByteArray & a)
这个声明是针对只读的输入流。输入流定义好之后,同样是设置流的版本号,要与输出端的一致。然后使用 >> 从输入流提取数据即可。上面函数打印的结
果如下:
1
125.789990
"This an example."
可见与输出函数里的完全一样。对于 Qt 程序的网络通信,都可以类似上面方法对数据进行打包和解析,是比较方便的。
QByteArray 有针对数据处理的一些函数,比如基 64
转换和压缩解压函数:fromBase64、toBase64、qCompress、qUncompress 等,这些函数可以到使用的时候再查帮助文档。
3.4.4 QByteArray和QString合理的使用方式
因为 QByteArray 既可以用作字符串,又可以用作字符数组,它的使用方式比较多。而且作为字符串时,它内部的字符编码格式又是不固定的,所以
QByteArray 有诸多的不确定性。Qt 帮助文档里面明确说了,如果要做字符串方面的处理,都应当使用 QString
,除非是嵌入式系统里面内存有限,不得不用 QByteArray 的情况。对于本地化编码的字符串,可以用 QString::fromLocal8Bit
函数将字符串源转为 QString 对象;对于 UTF-8 编码的字符串,可以用 QString::fromUtf8 函数实现转换。如果要反过来转换,就
用对应的 to*** 函数。通常情况下有这些函数就够用了。
对于文件读写和网络数据收发,这些一般都是用 QByteArray 对象作为输入输出缓冲区,并且可以利用 QDataStream
做串行化,将多个数据打包成 QByteArray 。通常情况下,对于纯字节数据的处理使用 QByteArray 。
在有些情况下,需要 QString 和 QByteArray 对多种编码格式字符串进行转换,需要二者协作,下面给个协作的示例:
void
TestCooperation()
{
//源字符串
QString strSrc = QObject::tr("1234abcd 千秋萬載 壹統江湖");
//转为 UTF-8
qDebug()<<strSrc.toUtf8();
//明确地转为 GB18030
QTextCodec *codecGB = QTextCodec::codecForName("GB18030");
QByteArray strGB = codecGB->fromUnicode(strSrc); //转为GB18030
qDebug()<<strGB;
qDebug()<<codecGB->toUnicode(strGB); //转回QString
//明确地转为 Big5
QTextCodec *codecBig5 = QTextCodec::codecForName("Big5");
QByteArray strBig5 = codecBig5->fromUnicode(strSrc); //转为Big5
qDebug()<<strBig5;
qDebug()<<codecBig5->toUnicode(strBig5); //转回QString
}
除了 QString 自带的 to*** 等函数实现不同字符编码的转换,更为专业的是 QTextCodec
类,专门用于不同文本编码格式的转换。上面示例函数以源字符串 strSrc 为起点,首先实现与 GB18030 编码互相转换,然后实现与 Big5
编码互相转换。
获取编码器的语法格式是:
QTextCodec *codecGB =
QTextCodec::codecForName("GB18030");
codecGB 是保存编码器的指针,静态函数 QTextCodec::codecForName 根据指定的编码名称获取相应的编码器,示例的是
"GB18030"。如果要将 QString 转成其他编码的 QByteArray,就用 fromUnicode 函数,反过来就用 toUnicode
函数。
上面对 GB18030 和 Big5 都做了示范,打印的结果如下图所示:
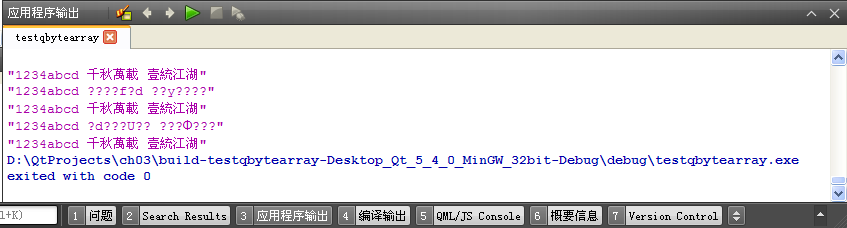
qDebug 打印 QString 对象和 UTF-8 字符串时汉字不会乱码,而 GB18030 和 Big5 等编码的汉字会乱码,只有数字、英文字符等
ASCII 码是正常显示的。
3.4.5 QByteArray示例代码
本节 QByteArray 示例就是以上 4 个测试函数的合集,下载地址:
https://lug.ustc.edu.cn/sites/qtguide/QtProjects/ch03/testqbytearray/testqbytearray.7z
下载之后解压到比如 D:\QtProjects\ch03\testqbytearray
文件夹里面,然后打开项目文件,阅读源代码。
这里主要把包含的头文件和 main 函数贴出来,4 个测试函数内容不重复贴了:
//testqbytearray.cpp
#include <QApplication>
#include <QTextBrowser>
#include <QDebug>
#include <QByteArray>
#include <QDataStream>
#include <QTextCodec>
void TestStr() //内码 UTF-8
{
...
}
//Qt 串行化方法
QByteArray TestSerialOut()
{
...
}
void TestSerialIn(const QByteArray& baIn)
{
...
}
//测试协作
void TestCooperation()
{
...
}
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
QString strText = QObject::tr("测试 QByteArray");
QTextBrowser tb;
tb.setText(strText);
tb.setGeometry(40, 40, 400, 300);
tb.show();
//str
TestStr();
qDebug()<<endl;
//serialization
QByteArray baSerial = TestSerialOut();
//baSerial 可用于网络发送
//接收到 baSerial 之后解析
TestSerialIn(baSerial);
qDebug()<<endl;
//测试协作
TestCooperation();
return a.exec();
}
概括来说,QByteArray 作为字符串使用时,相关函数类似上一节 QString 的函数。因为 QByteArray 自身具有很多的不确定性,所以涉及到字符串处理的都优先用 QString。
在文件输入输出和网络数据收发等情景,一般用 QByteArray 作为缓冲区,配合 QDataStream 串行化使用。
对于特定字符编码的转换,Qt 提供专门的类 QTextCodec ,可以参考本节的示例进行转码。


