9.2 顺序容器:QVector、QStack
本节介绍剩下的两种顺序容器,向量 QVector 和 栈 QStack。向量 QVector
本质就是封装好的数组,向量的相邻元素在内存里是连续存储的,可以用数组下标访问,其读取和修改元素的操作是非常快的,与C++数组是一样的,但是随机插入元素和随机删除
元素需要大量腾挪后面的元素,所以不同的数据结构有不同的应用场景。如果读写操作频繁,但是随机增删操作比较少,那么这种场景就很适合向量。栈 QStack
是向量的派生类,继承了向量的全部功能,并添加了几个进栈、出栈的操作函数。
本节内容安排:9.2.1 小节介绍向量 QVector 的功能,通过城市经纬度查询示例学习向量和嵌套容器的使用; 9.2.2 小节简单介绍栈
QStack 的功能,利用栈实现树形结构的遍历; 9.2.3 小节对五种顺序容器进行对比归纳,测试它们常用操作函数的执行效率。
9.2.1 向量 QVector
向量 QVector 就是封装好的数组,不仅支持 C++ 基本类型和 Qt
常见的数据类型,对于自定义类型也可以支持,如果希望保存大量的自定义类型对象并且能高效读写,就可以使用向量。Qt 容器还可以进行嵌套,比如下面代码就定义了
10*10 的二维向量:
QVector<
QVector<int> > vc;
vc.resize(10);
for(int i=0; i<10; i++)
{
vc[i].resize(10);
}
容器嵌套定义时,要注意在两层尖括号中间加空格,避免编译器把容器嵌套识别为流操作符。二维向量分配存储空间完成后就和二维数组用起来差不多。向 量
QVector 与之前介绍的列表 QList 类似,只能存储值类型,即类型 T 必须支持默认构造函数、复制构造函数和等于号赋值函数。
下面我们分类列举向 量模板类的功能函数:
(1)构造函数
QVector() //默认构造函数
QVector(int size) //初始化 size 个元素的向量,元素初始值为类型 T
默认构造函数生成的值
QVector(int size, const T & value) //用 value 值初始化
size 个元素的向量
QVector(const QVector<T> & other) //复制构造函数
QVector(QVector<T> && other) //移动构造函数
QVector(std::initializer_list<T> args) //初始化列表构造函数
~QVector() //析构函数
第一个是默认构造函数,用于支持容器嵌套;
第二个是构造 size 个元素的向量,每个元素初始值都是类型 T 默认构造函数设定的数值;
第三个是构造 size 个元素的向量,并且每个元素都设置为 value 值;
第四个是复制构造函数,将参数 other 里的元素都复制一份给新向量;
第五个是移动构造函数,将参数 other 里的元素都移动到新向量里面,旧的 other 向量内容清空;
第六个是初始化列表构造,支持根据类似 {1, 2, 3} 的初始化表构造新的向量;
第七个是析构函数。
需要注意第二和第三个构造函数,不仅仅是分配空间,而且填充了 size 个元素。
(2)添加和分配空间函数
将元素添加到向量头部、尾部的函数如下:
void append(const T &
value) //将 value 添加到向量尾部
void push_back(const T & value) //将 value
添加到向量尾部,STL风格
void prepend(const T & value) //将
value 添加到向量头部
void push_front(const T & value)//将 value
添加到向量头部,STL风格
通常情况下,添加到向量尾部的开销比较小,而添加到头部意味着将向量原有的元素都向后平移,开销会很大。
在向量中间位置插入一个元素或多个元素的函数如下:
void insert(int i, const T & value)
void insert(int i, int count, const T & value)
第一个 insert() 是将一个 value 插入到序号 i 的位置,原本序号 i 以及后面的元素都平移,然后把 value 复制到序号 i 的位置。
第二个 insert() 是将 count 个 value 值插入到序号 i 的位置,插入后从序号 i 到 i+count-1 序号都是等于 value
值的元素。
insert() 函数支持的最大序号是 size() ,即元素总数,如果 i 等于 size() ,那么元素添加到向量末尾。如果 i
>size() ,程序会因为访问越界而崩溃。其他带序号 i 的函数,序号范围仅支持 0 ~ size()-1 ,只有 insert()
例外多支持一个添加到末尾。
这里着重说明一下,向量为了提升访问效率,绝大部分带序号 i
的函数都不做越界判断,一旦出现越界程序就会崩溃,这点与普通数组是一样的!
向量还支持自动填充元素:
QVector<T> & fill(const T
& value, int size = -1)
如果 fill() 第二个参数为默认的 -1,那么向量内所有元素都被填充为数值 value;
如果第二个参数不是 -1,那么向量首先进行增长或裁剪,使得元素个数正好是 size 计数,然后将向量的 size 个元素数值设置为 value。
获取向量的元素数量(即向量的长度、尺寸)函数如下:
int count() const
int size() const
int length() const
这三个函数是一样的,都是向量里的元素计数。如果希望改变向量元素的计数(长度、尺寸),可以用下面的重置尺寸函数:
void resize(int size)
重置向量尺寸后,向量的元素就变成 参数里的 size 个,如果元素变多,那么使用类型 T
的默认构造函数设置末尾的新元素,如果元素变少了,那么后面的元素会被删除掉。
resize()
函数会直接影响向量里的元素个数,如果希望在不影响元素个数的情况下扩容,那么也有相应的函数。下面三个函数就是用于设置、获取容量,但不影响元素个数:
void reserve(int size) //为 size
个元素分配空间,但是不增加任何新元素,向量的元素总数不变
int capacity() const
//查询向量内部的存储容量,容量一般大于等于 count()
void squeeze()
//释放不需要的额外容量,与 reserve() 函数功能相反
这三个容量操作的函数不会影响向量中的元素总数,也不改变任何元素的数值。reserve( size ) 是为
size 个数元素提前分配空间,如果参数里的个数小于向量原本的尺寸,那么该函数不执行任何操作,不会截断向量;如果参数 size
大于向量原本的尺寸,那么提前分配空间。reserve( size ) 仅仅是提前分配空间,不会为向量添加新元素,向量的元素计数
count () 是不变的。
capacity() 用于查询向量的存储空间,一般大于等于 count() 。
squeeze() 用于释放额外空间,与 reserve( size ) 的操作正好相反。
这里需要特别注意 resize( size) 和 reserve( size ) 的区别:
resize( size ) 直接影响元素个数,如果参数里数值比旧的尺寸大,那么扩容并添加新元素,向量元素总数变为参数指定的个数;
如果resize( size ) 参数里的数值比旧的尺寸小,那么对向量进行截断,只保留参数里指定个数的元素。
而 reserve( size )
无论参数里数值是什么,都不会改变向量元素的个数,也不会修改任何元素的数值,仅仅用于提前分配空间,但不会添加任何的新元素。如果在添加元素之前,提前知道向量大概的元
素总数,那么用 reserve( size ) 提前分配空间可以避免添加新元素过程中的向量自动扩容操作。
为区别这两个函数,读者可以测试下面的错误代码:
QVector<int> va = {1, 2, 3};
va.reserve(10);
va[4] = 1; //!!!错误示范
reserve(10) 会为向量扩容,但没有新增元素,上面最后一句 va[4] = 1 是数组越界,会导致程序崩溃。
如果使用 resize( 10 ),那么上面代码就是合法的,因为 resize( 10 ) 会为向量新添加 7 个元素到后面,va[4] 就不会越界。
(3)移除和删除函数
在调用移除和删除函数之前,一定要确保向量非空,用 ! empty() 或 ! isEmpty() 判断,不能对着没有元素的向量进行删除元素。
如果希望从向量卸下元素并返回该元素值,使用 take**() 函数:
T takeAt(int i) //卸下序号 i 位置元素,并返回该元素
T takeFirst() //卸下向量的头部元素,并返回该元素
T takeLast() //卸下向量的尾部元素,并返回该元素
不返回元素,直接删除元素的函数如下:
void remove(int
i) //删除序号 i 位置元素
void removeAt(int i) //删除序号 i 位置元素
void remove(int i, int count) //从序号 i 位置开始删除参数里 count
个数的元素
void removeFirst() //删除头部元素
void pop_front() //删除头部元素,STL风格
void removeLast() //删除尾部元素
void pop_back() //删除尾部元素,STL风格
向量从尾部删除元素的效率高,但是删除头部或中间的元素,意味着将后面大批量元素往前复制腾挪,效率就比较低了。 take**() 函数与
remove**() 函数效率差不多,仅仅是多个返回值。
如果希望删除匹配的一个或多个元素,使用下面的函数:
bool removeOne(const T &
t) //如果向量里存在等于 t 的元素就删除并返回 true,否则找不到返回 false
int removeAll(const T & t)
//删除向量中所有等于 t 的元素,并返回删除的数量
removeOne( t ) 和 removeAll( t ) 函数需要元素类型 T 支持双等号比较函数 operator==() 。
如果需要清空向量,删除所有元素,那么使用如下函数:
void clear()
(4)访问和查询函数
访问指定序号 i 元素的函数如下:
const T & at(int i)
const //返回序号 i 元素的常量引用,效率最高,但是不做越界判断!
T value(int i) const
T value(int i, const T & defaultValue) const
at( i ) 的函数效率最高,但是它不检查数组越界,一旦越界程序就会崩溃,对于该函数必须确保 0 <= i < size() 。
两个 value( ) 函数都会检查参数的序号是否越界,第一个 value( i ) 如果序号越界,返回类型 T 默认构造函数设置的元素数值,第二个
value( i, defaultValue ) 如果发生序号 i 越界,那么返回参数里指定的数值 defaultValue
。如果不发生越界,两个 value() 函数都返回正常的序号 i 位置元素数值。
快速获取向量头部、尾部元素的函数如下:
T & first()
//头部元素的读写引用
const T & first() const //头部元素的只读引
用
T & front() //头部元素的读写引用,STL风格
const_reference front() const
//头部元素的只读引用,STL风格
T & last() //尾部元素的读写引用
const T & last() const //尾部元素的只读引用
reference back() //尾部元素的读写引用,STL风格
const_reference back() const
//尾部元素的只读引用,STL风格
STL风格函数返回值的 reference 是类型定义,等同 T & ; const_reference 也是类型定义,等同
const T & 。
判断向量是否为空的函数如下:
bool empty() const
//判断向量是否为空,STL风格
bool isEmpty() const //判断向量是否为空
查询向量里是否包含 value 数值或查询有几个等于 value 数值的元素,使用下面的函数:
bool contains(const T & value)
const //查询向量是否包含等于 value 数值的元素,有就返回 true,没有就返回 false
int count(const T & value) const
//查询向量包含几个等于 value 数值的元素,有就返回个数,没有就返回 0
凡是参数里带 value 的查询函数、移除或删除函数,都需要元素类型 T 支持双等号比较函数 operator==() 。
如果需要查询等于 value 数值的元素的序号,使用下面两个函数:
int indexOf(const T & value, int
from = 0) const //从前到后查询,从 from 序号开始查找等于 value
的元素序号,找不到时返回 -1
int lastIndexOf(const T & value, int from = -1)
const //从后向前查询,从 from 序号开始倒着查找等于 value 的元素序号,找不到就返回 -1
indexOf() 是按照序号从小到大查找,lastIndexOf() 是反过来,按照序号从大到小来查找,这两个函数如果找不到匹配的元素,就会返回
-1,要注意返回值的判断。
查询头部和尾部是否等于某数值的快捷函数如下:
bool startsWith(const T & value)
const //查询头部元素是否等于 value
bool endsWith(const T & value)
const //查询尾部元素是否等于 value
向量类还有特殊的函数,可以直接获取内部的连续存储空间指针:
T * data()
//获取向量内部存储空间的读写指针,可以修改元素值
const T * data() const
//获取向量内部存储空间的只读指针
const T * constData() const //获取向量内部存储空间的只读指针
data() 和 constData() 返回值就是向量里真实的数组指针,如果读者希望自己直接用指针操作各个元素,就可以用这三个函数。
一般是不建议直接调用这三个函数,因为如果处理不当就容易出现越界,而且不能直接为存储空间扩容。
(5)获取子序列、替换和交换函数
如果希望从向量复制出来一个子序列的向量,那么使用如下函数:
QVector<T> mid(int pos, int length
= -1) const //从序号 pos 开始复制 length 个数的元素到新向量,返回新向量
mid() 函数专门提取子序列向量,从 pos 开始复制 length 个数的元素到新向量里,返回新向量。如果 length 为 -1
或超出原向量的界限,那么从 pos 开始的所有元素都会复制到新向量里。
修改序号 i 位置元素数值的函数如下:
void replace(int i, const T & value)
注意序号 i 不能越界,必须合法,即 0 <= i < size() 。
如果希望与其他向量交换所有的元素,使用下面函数:
void swap(QVector<T> & other)
swap() 函数执行效率非常高,并且不会失败。
(6)运算符函数
对于运算符函数,我们以下面三个向量来举例说明:
QVector<int> va = {1, 2, 3};
QVector<int> vb = {4, 5, 6};
QVector<int> vc;
运算符使用示范如下表所示:
| 运算符函数 |
举
例 |
描述 |
| bool operator!=(const QVector<T> & other) const |
va != vb; |
va 和 vb 两个向量有元素不同,结果为 true。 |
| QVector<T> operator+(const QVector<T> & other)
const |
vc = va + vb; |
va 和 vb 复制拼接后生成新向量,赋值给 vc。 |
| QVector<T> & operator+=(const QVector<T> &
other) |
va += vb; |
复制 vb 所有元素追加到 va 末尾。 |
| QVector<T> & operator+=(const T & value) |
va += 100 ; |
添加一个元素 100 到 va 末尾。 |
| QVector<T> & operator<<(const QVector<T>
& other) |
va << vb; |
复制 vb 所有元素追加到 va 末尾。 |
| QVector<T> & operator<<(const T & value) |
va << 100; |
添加一个元素 100 到 va 末尾。 |
| QVector<T> & operator=(const QVector<T> &
other) |
vc = va; |
va 所有元素都复制一份给 vc,va本身不变。二者相等。 |
| QVector<T> operator=(QVector<T> && other)
//移动赋值 |
vc = std::move(va) ; |
va 所有元素都移动给 vc, va本身被清空。 |
| bool operator==(const QVector<T> & other) const |
va == vb; |
va 和 vb 有元素不同,结果为 false。
只有两个向量的所有元素相等并且顺序一样,它们才能算相等。 |
| T & operator[](int i) |
va[0] = 100;
|
获取序号为 i 的元素的读写引用,可修改向量元素。 |
| const T & operator[](int i) const |
qDebug()<<va[0] ; |
获取序号为 i 的元素的只读引用。 |
上表双等号函数判断的条件非常严苛,只有在两个向量的元素完全相等、顺序一样、元素个数一样的情况下,两个向量才会相等。
对于带序号 i 的中括号函数(数组下标访问函数),要求序号必须满足 0 <= i < size(),如果序号不合法,出现越界访
问,程序就会崩溃。
(7)迭代器函数
为了兼容 STL,向量也是一样带有迭代器的,向量内部自带的迭代器类型如下:
typedef iterator
//读写迭代器,STL风格
typedef Iterator //读写迭代器,Qt 风格
typedef const_iterator //只读迭代器,STL风格
typedef ConstIterator //只读迭代器,Qt风格
迭代器使用示范如下:
QVector<int> va = {1, 2, 3};
QVector<int>::iterator it = va.begin();
while( it != va.end() )
{
qDebug()<< (*it);
it++; //下一个
}
获取向量头部、尾部后面假想元素迭代器的函数如下:
iterator begin()
//指向头部的读写迭代器
const_iterator begin() const
//指向头部的只读迭代器
const_iterator cbegin() const
//指向头部的只读迭代器
const_iterator constBegin() const //指向头部的只读迭代器,Qt
风格
iterator end() //指向尾部后面假想元素的读写迭代器
const_iterator end() const
//指向尾部后面假想元素的只读迭代器
const_iterator cend() const
//指向尾部后面假想元素的只读迭代器
const_iterator constEnd() const
//指向尾部后面假想元素的只读迭代器,Qt风格
注意 *end() 返回的迭代器通常只用于做不等于判断,它指向的东西根本不存在, *end() 仅用于越界判断。
虽然获取头部、尾部迭代器的函数多,其实功能类似,起了一堆名字是方便兼容 STL 风格函数命名。
利用迭代器插入一个或多个元素的函数如下:
iterator insert(iterator before, const T
& value) //在 before 指向的元素前面插入元素 value
iterator insert(iterator before, int count, const T
& value) //在 before 指向的元素前面插入 count 个数的 value 元素
insert() 迭代器函数返回值就会自动指向新插入的元素,如果插入多个元素,就指向新插入的第一个元素,参数里迭代器 before
不能再使用。一定要使用返回值里的迭代器进行后续遍历操作。
利用迭代器删除元素的函数如下:
iterator erase(iterator
pos) //删除 pos 指向的一个元素,返回值指向下一个元素,可能指向尾部后面假想元素
iterator erase(iterator begin, iterator end) //删除从参数
begin 到参数 end 的元素,但是参数 end 元素不删除,总是返回参数 end
第一个 erase() 删除参数 pos 指向的一个元素,返回下一个元素的迭代器,返回值可能是指向尾部后面假想元素。
第二个 erase() 删除从参数 begin 到参数 end 的多个元素,但是参数 end 指向的元素不删除,该函数总是返回参数 end 迭代器。
一般向量很少使用迭代器访问,因为使用数组下标形式更直接而且高效。
(8)容器类型转换函数
如果希望将向量转为列表或标准库的向量,使用下面函数:
QList<T> toList()
const //转为 Qt 列表
std::vector<T> toStdVector()
const //转为标准库的向量
向量类还提供了静态成员函数,实现将参数里类型转为向量类型,返回值就是新的向量:
QVector<T> fromList(const
QList<T> & list) //将参数里的列表转为向量,返回值是新向量
QVector<T> fromStdVector(const
std::vector<T> & vector) //将参数里的标准库向量转为 Qt 向量
列表的好处是针对头部插入元素有优化,向量头部插入元素需要大量元素向后复制腾挪,向量头部元素的增删不如列表效率高。
(9)其他内容
向量类还附带了两个友元函数,是流操作符重载函数,支持数据流的输出、输入,
QDataStream &
operator<<(QDataStream & out, const QVector<T> &
vector) //输出
QDataStream & operator>>(QDataStream & in,
QVector<T> & vector) //输入
这些流操作符函数正常运行的前提是元素类型 T 必须支持数据流的输入和输出。C++ 基本类型和 Qt 常见数据类型都支持,如果是自定义类型那么必须类似重
载 operator<<() 和 operator>>() 函数。
向量与列表一样都支持排序函数:
void qSort(Container & container) //排序
void qStableSort(Container & container) //稳定排序
排序函数要求容器的元素类型 T 必须支持小于号函数 operator<(),用于比较元素大小。Qt
调用的小于号函数原型是两个参数的全局 operator<() 函数,不是成员函数,应该在类外面声明并定义下面的小于号函数:
bool operator< ( const T &t1, const T &t2
)
一般要将该函数声明为 T 类型的友元函数,方便访问私有变量。
最后我们梳理一下,如果自定义类型希望能够完美地和 QVector 配合使用,那么需求如下:
① 必须是可赋值类型,需要默认构造函数、复制构造函数、赋值函数 operator=() ;
② 如果希望支持查询函数,需要双等号函数 operator==();
③ 如果希望支持排序函数,需要全局小于号函数 operator< ( const T &t1, const T &t2
) ;
④ 如果希望支持 QDataStream 数据流输入输出,那么添加友元函数 operator<<() 和
operator>>() 。
第一条是必须实现的函数,后面三条是建议实现的函数。
对于自定义类型支持 QVector ,可以参考 9.1.1 小节的示例,因为 QList 和 QVector 对自定义类型的要求是一样的。
本小节示例实现一个查询城市经纬度的功能,并示范嵌套容器的使用。在开始例子之前,请读者到下面网址下载一个文本文件:
https://qtguide.ustclug.org/QtProjects/ch09/cityposition/position.txt
position.txt 保存了全国各省市的经纬度,里面的内容举例如下:
安徽省 合肥市 31 50 117 15
安徽省 安庆市 30 32 117 3
安徽省 池州市 30 40 117 29
安徽省 六安市 31 46 116 30
每行文本分别是省名称、市名称、纬度的度和分、经度的度和分。比如合肥市就是纬度 31°50′,经度 117°15′
。所有的行都是这种格式,方便我们用程序加载。
下载 position.txt 之后,我们打开 QtCreator,新建一个 Qt Widgets Application
项目,在新建项目的向导里填写:
①项目名称 cityposition,创建路径 D:\QtProjects\ch09,点击下一步;
②套件选择里面选择全部套件,点击下一步;
③基类选择 QWidget,点击下一步;
④项目管理不修改,点击完成。
新建项目之后,我们把 position.txt 复制到项目文件夹 D:\QtProjects\ch09\cityposition 里面。
我们点击 QtCreator 菜单“文件”-> “新建文件或项目”,进入新建对话框,
在对话框左边选择“文件和类”里的“Qt”栏目,然后在对话框中间选择“Qt Resource File”:
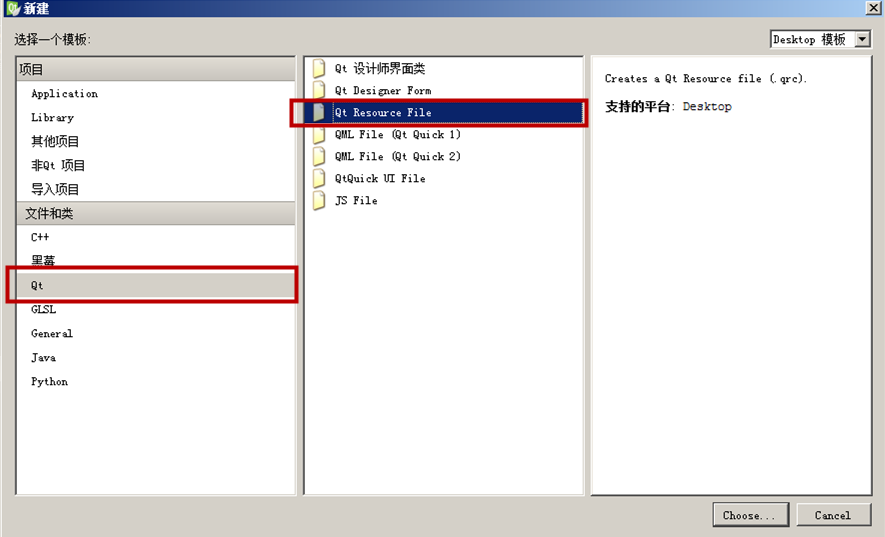 点击下面 Choose... 按钮,进入文件名称路径设置页面,名称里填写 res.qrc :
点击下面 Choose... 按钮,进入文件名称路径设置页面,名称里填写 res.qrc :
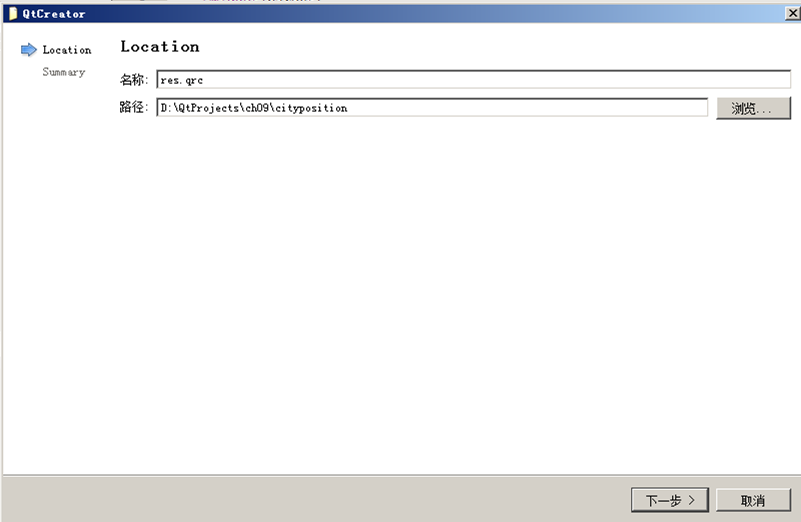 点击下一步按钮,进入项目管理界面:
点击下一步按钮,进入项目管理界面:
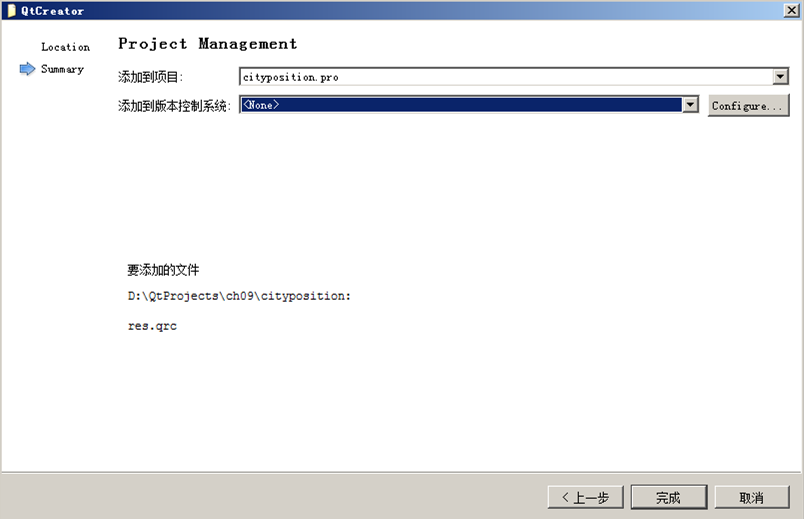 项目管理界面不需要修改,直接点击完成,这样就添加了 res.qrc 文件到项目里了。
项目管理界面不需要修改,直接点击完成,这样就添加了 res.qrc 文件到项目里了。
添加 res.qrc 文件之后,自动进入该文件编辑界面,我们在 QtCreator 左侧项目管理栏,右击 res.qrc 文件,
在右键菜单选择“添加现有文件...”:
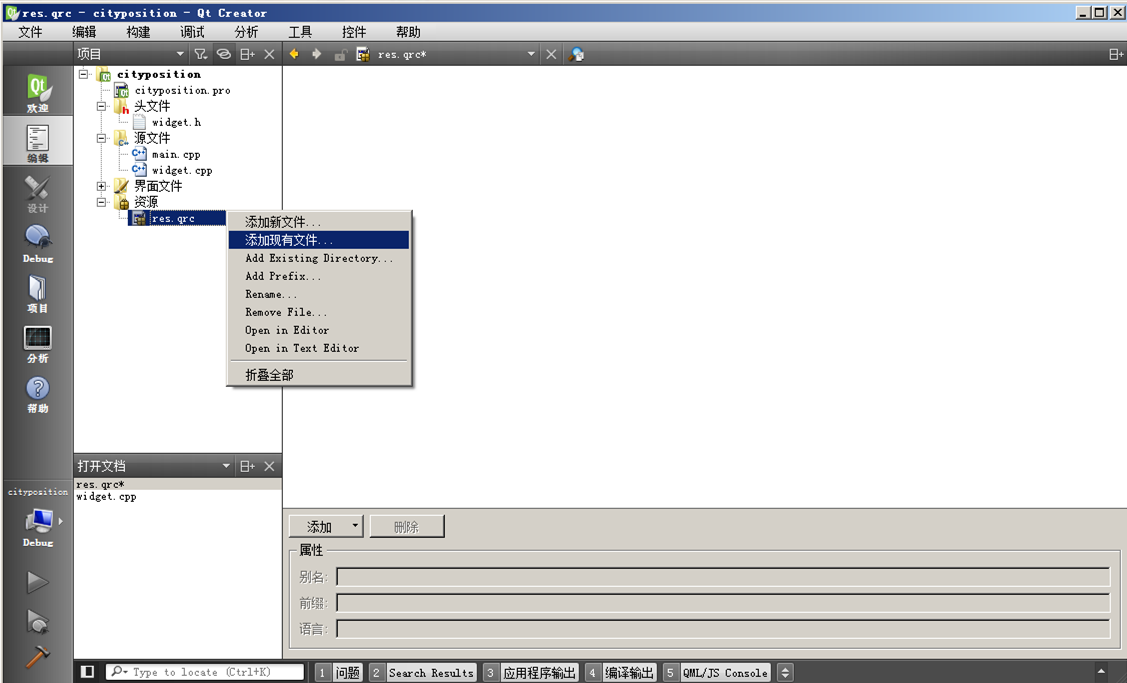 在弹出的添加现有文件对话框里面,选择 position.txt 添加到资源文件里面:
在弹出的添加现有文件对话框里面,选择 position.txt 添加到资源文件里面:
 点击上面对话框的打开按钮,然后我们就可以看到该记事本文件成功添加到资源文件里了:
点击上面对话框的打开按钮,然后我们就可以看到该记事本文件成功添加到资源文件里了:
 我们保存该资源文件,然后就可以关闭它了,将 position.txt 添加到资源文件里,项目编译之后就会将该文件嵌入到生成的可执行目标程序里,程序里可以
使用下面路径读取该文件:
我们保存该资源文件,然后就可以关闭它了,将 position.txt 添加到资源文件里,项目编译之后就会将该文件嵌入到生成的可执行目标程序里,程序里可以
使用下面路径读取该文件:
:/position.txt
接下来我们编辑 widget.ui 界面文件,参考下图拖入控件:
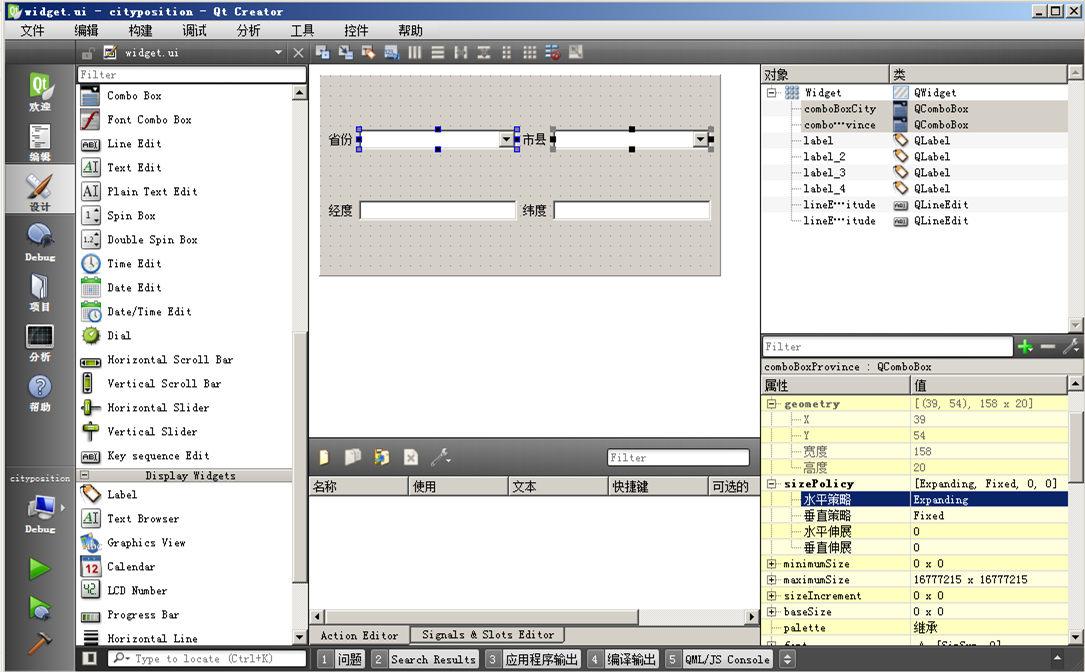 第一行是两个标签和两个组合框,标签文本分别为“省份”、“市县”,组合框对象名分别为
comboBoxProvince、comboBoxCity,这里需要将两个组合框的 sizePolicy 的水平策略都修改为 Expanding
自动拉伸模式,方便与第二行的单行编辑器对齐。
第一行是两个标签和两个组合框,标签文本分别为“省份”、“市县”,组合框对象名分别为
comboBoxProvince、comboBoxCity,这里需要将两个组合框的 sizePolicy 的水平策略都修改为 Expanding
自动拉伸模式,方便与第二行的单行编辑器对齐。
第二行是两个标签和两个单行编辑器,标签文本分别为“经度”、“纬度”,单行编辑器对象名为
lineEditLongitude、lineEditLatitude。
窗口整体使用一个栅格布局,窗口大小 400*200 。
这个界面用组合框存储全国所有的省份和市县,当省份改变时,自动加载该省的市县;用户选择了省份和市县之后,下面单行编辑器自动显示该市县的经纬度。
下面我们开始 编辑代码,首先是头文件 widget.h 的代码:
#ifndef
WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <QVector>
namespace Ui {
class Widget;
}
class Widget : public QWidget
{
Q_OBJECT
public:
explicit Widget(QWidget *parent = 0);
~Widget();
private slots:
//省份变化时,自动加载该省的市县
void onProvinceIndexChange(int index);
//市县变化时,自动显示市县的经纬度到编辑框
void onCityIndexChange(int index);
private:
Ui::Widget *ui;
//保存省份名称
QVector<QString> m_vProvinces;
//二维向量保存市县名称
QVector< QVector<QString> > m_vCities;
//二维向量保存市县的经度
QVector< QVector<double> > m_vLongitudes;
//二维向量保存市县的纬度
QVector< QVector<double> > m_vLatitudes;
//从 position.txt 加载各省市及其经纬度
void loadPositions();
};
#endif // WIDGET_H
该文件添加了向量模板类的头文件引用。Widget 类声明里的私有槽函数都是手动添加的,onProvinceIndexChange(int) 用于关联省份组合框的序号变化信号,onCityIndexChange(int) 用于关联市县组合框的序号变化信号,当用户选择省份时自动更新该省的市县,用户选择市县时,自动显示该市县的经纬度到编辑框。
类的私有变量里,添加了一维字符串向量 m_vProvinces ,保存省份的名称列表;
添加了二维向量 m_vCities 保存市县名称, m_vLongitudes 保存市县经度,m_vLatitudes 保存市县纬度,二维向量定义时要注意在两层尖括号中间加空格,防止编译器将二维向量的尖括号识别为流操作符。这里的二维向量,第一维是省份的序号,第二维是该省市县的序号。
最后的私有函数 loadPositions() 在窗口构建时从资源文件加载全国所有的省份和市县信息。
下面分段编辑源文件 widget.cpp 的代码,首先是头文件包含、构造函数、析构函数:
#include "widget.h"
#include "ui_widget.h"
#include <QDebug>
#include <QFile> //文件
#include <QTextStream>//文本流
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
ui->setupUi(this);
//设置编辑框为只读
ui->lineEditLongitude->setReadOnly(true);
ui->lineEditLatitude->setReadOnly(true);
//从资源文件 position.txt 读取省市经纬度
loadPositions();
//关联信号,省份组合框序号变化
connect(ui->comboBoxProvince, SIGNAL(currentIndexChanged(int)),
this, SLOT(onProvinceIndexChange(int)) );
//市县组合框序号变化
connect(ui->comboBoxCity, SIGNAL(currentIndexChanged(int)),
this, SLOT(onCityIndexChange(int)) );
}
Widget::~Widget()
{
delete ui;
}
该文件添加了调试打印类、文件类和文本流的头文件包含。
构造函数里先将经度、纬度编辑框设置为只读,防止显示市县经纬度后被用户修改,因为市县经纬度是固定值。
然后调用 loadPositions() 加载全国所有省份、市县的经纬度信息。
加载经纬度信息之后,关联省份组合框的序号变化信号到槽函数 onProvinceIndexChange(int);
关联市县组合框的序号变化信号到槽函数 onCityIndexChange(int) 。
构造函数里先加载经纬度信息,后关联信号到槽函数,是避免添加省份或市县组合框条目时触发序号变化信号,因为数据没加载完,如果冒然触发序号变化关联的槽函数,槽函数容易出现越界访问或者读取不了经纬度。
析构函数是默认代码,没有修改。
下面手动编辑加载全国省份和市县经纬度信息的函数:
//从资源文件 position.txt 读取省市经纬度
void Widget::loadPositions()
{
//打开资源里的文件
QFile fileIn( ":/position.txt" );
//资源文件打开一般不需要判断,只要文件名对就可以打开
fileIn.open( QIODevice::ReadOnly );
//定义文本流
QTextStream tsIn(&fileIn);
tsIn.setCodec( "UTF-8" ); //该文件使用 UTF-8 文本编码
//为二维向量的第一维省份添加元素空间,这样后面才能使用中括号访问
m_vCities.resize( 40 );//全国省份目前只有34个,分配 40 保证够用
m_vLongitudes.resize( 40 );
m_vLatitudes.resize( 40 );
//定义变量
QString strProvBefore;//保存前一行记录的省份,用于判断是否应该添加新省份了
QString strProvCur; //当前行加载的省份
QString strCity; //当前行加载的市县
int nLonD; //经度的度
int nLonM; //经度的分
int nLatD; //纬度的度
int nLatM; //纬度的分
//记录当前省份的序号
int nProvIndex = -1;
//开始读取,文本流不结束就一直读
while( !tsIn.atEnd() )
{
//依次读取省份、市县、纬度的度和分、经度的度和分
tsIn>>strProvCur>>strCity
>>nLatD>>nLatM
>>nLonD>>nLonM ;
//如果当前省份不等于前一个省份,需要新增省份
if( strProvBefore != strProvCur )
{
nProvIndex++; //省份序号增加
strProvBefore = strProvCur; //保存省份,用于下一行记录判断
//添加新的省份
m_vProvinces<<strProvCur; //一维向量不需要提前分配,自动分配空间并追加元素
}
//无论省份新旧,都要添加市县、经度、纬度
//添加市县
m_vCities[nProvIndex] << strCity;
//添加纬度,转为浮点数的度
m_vLatitudes[nProvIndex] << nLatD + (double)nLatM/60.0;
//添加经度
m_vLongitudes[nProvIndex] << nLonD + (double)nLonM/60.0;
}
//从文件加载完毕
//省份组合框的内容是固定的,直接添加
for(int i=0; i<m_vProvinces.count(); i++)
{
ui->comboBoxProvince->addItem( m_vProvinces[i] );
}
//设置省份序号
ui->comboBoxProvince->setCurrentIndex( 0 );
//手动调用省份变化槽函数,显示第一个省份的所有市县到组合框
onProvinceIndexChange( 0 );
//手动调用市县变化槽函数,显示经纬度
onCityIndexChange( 0 );
//打印省份计数
qDebug()<<tr("加载完毕,省份计数: %1").arg( m_vProvinces.count() );
}
该函数首先定义文件输入对象 fileIn,文件名为资源文件 ":/position.txt" ,然后直接打开该文件,对于资源里的文件,我们不需要判断是否打开成功,因为该文件总是存在的,并且格式已知,也不需要进行输入异常判断,因为我们程序员可以控制 ":/position.txt" 文件的内容,不行可以在程序编译之前纠正该文件内容。程序运行时资源里的文件都是只读的,所以不需要考虑数据源污染问题。
打开文件之后,以该文件对象定义输入文本流,设置文本编码格式 UTF-8 。
然后提前为三个二维向量增加了第一维的 40 个元素,全国目前省份只有 34 个,添加 40 个已经很富余了,保证后面用中括号访问时不会越界。
接下来定义了三个字符串,strProvBefore 保存前一行记录的省份,strProvCur 保存当前行的省份,strCity 保存当前的市县。当上一行的省份不同于当前行的省份时,我们就知道需要为一维向量 m_vProvinces 添加新的省份名称,省份序号也就加一,然后新省份的市县、经纬度就保存到二维向量的新序号记录行里面。
然后定义了经度的度、分,纬度的度、分变量,方便从文件读取市县的经纬度。
我们定义省份序号 nProvIndex 从 -1 开始,然后开始用 while 循环加载 position.txt 文件:
我们从文件当前行里面加载省份名称、市县名称、纬度的度值和分值、经度的度值和分值;
然后判断 strProvBefore 是否与 strProvCur 不一样:
如果不一样就将省份序号加一,保存当前行的省份给 strProvBefore 用于下轮循环判断,将新省份名称添加到向量 m_vProvinces。
因为 nProvIndex 总是与当前的省份序号同步,所以无论新旧省份,都将市县的名称添加到 m_vCities[nProvIndex] 记录行里面,计算纬度浮点数值保存到 m_vLatitudes[nProvIndex] 记录行,计算经度浮点数值保存到 m_vLongitudes[nProvIndex] 记录行。
当文件所有内容读取完毕时,结束循环。
这样全国所有省份市县信息都加载到四个向量里面了。
我们将省份名称循环添加为省份组合框的条目,将当前省份条目序号设为 0 ;
然后手动调用了省份序号变化关联的槽函数和市县序号变化的槽函数,用于填充市县组合框,并显示第一个市县的经纬度到编辑框。
最后打印了实际加载的省份计数。
下面我们编辑关联省份组合框序号变化信号的槽函数:
//根据省份序号变化,自动加载该省的市县
void Widget::onProvinceIndexChange(int index)
{
if(index < 0) return; //序号不合法,不处理
//清空市县组合框
ui->comboBoxCity->clear();
//根据省份序号,加载该省的市县到市县组合框
//该省的市县计数
int nCount = m_vCities[index].count();
for(int i=0; i<nCount; i++)
{
//第一维是省序号,第二维是市县序号
ui->comboBoxCity->addItem( m_vCities[index][i] );
}
//设置默认市县的序号
ui->comboBoxCity->setCurrentIndex( 0 );
}
该函数首先对序号进行判断,如果序号不合法直接返回;序号合法才进行后续操作。
当省份序号变化时,我们先清空市县组合框的内容;
然后获取新省份对应的市县计数;
将新省份的市县名称全部添加到市县组合框,完成市县组合框的更新;
最后设置默认的市县为该省打头的第一个市县。
最后我们编辑关联市县组合框序号变化的槽函数:
//根据市县序号变化,自动显示市县的经纬度到编辑框
void Widget::onCityIndexChange(int index)
{
if(index < 0) return; //序号不合法,不处理
//获取省份序号,为第一个纬度
int nProvIndex = ui->comboBoxProvince->currentIndex();
//设置经度编辑框
ui->lineEditLongitude->setText(
tr("%1").arg( m_vLongitudes[nProvIndex][index] ) );
//设置纬度编辑框
ui->lineEditLatitude->setText(
tr("%1").arg( m_vLatitudes[nProvIndex][index] ) );
}
该函数第一件事也是判断序号,如果序号不合法就直接返回,如果序号合法才进行后续操作。
我们获取当前省份序号 nProvIndex ,市县的序号就是参数里 index;
当前省市的经度就是 m_vLongitudes[nProvIndex][index] ,显示到经度编辑框;
当前省市的纬度就是 m_vLatitudes[nProvIndex][index],显示到纬度编辑框。
我们更换省份时,会自动加载该省的市县,而市县组合框变化时,就会自动显示该省指定市县的经纬度。
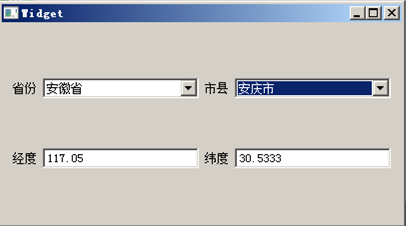
示例代码讲解到这,我们构建运行示例,当选择的省份、市县变化时,经纬度会同步更新:
9.2.2 栈 QStack
QStack 是向量 QVector 的派生类,继承了基类全部的功能,仅仅添加少许的栈操作函数。首先是进栈、出栈的函数:
void push(const T & t) //将 t 添加到栈顶
T pop() //取出栈顶元素并返回
还有两个获取栈顶元素引用的函数:
T & top() //获取栈顶元素的读写引用
const T & top() const //获取栈顶元素的只读引用
另外栈重载了基类的交换函数,用于和另一个对象互换所有元素:
void swap(QStack<T> & other)
交换函数的执行效率非常高,并且不会失败。
栈自身的新函数就这些,其他功能都可以使用基类的函数实现。
栈的用途非常广泛,比如我们可执行程序所有的函数调用都是基于栈的,栈也可以实现遍历树形结构,能够取代递归函数调用。本小节的示例我们就使用栈来遍历简单的树,示例使用的二叉树同 8.3.3 节的树,利用栈实现树遍历的算法代码参考:
https://www.cnblogs.com/jeavenwong/p/8176808.html
下面开始示例,打开 QtCreator,新建一个 Qt Widgets Application 项目,在新建项目的向导里填写:
①项目名称 stacktraversal,创建路径 D:\QtProjects\ch09,点击下一步;
②套件选择里面选择全部套件,点击下一步;
③基类选择 QWidget,点击下一步;
④项目管理不修改,点击完成。
我们打开 widget.ui 界面文件,按照下图拖入控件:
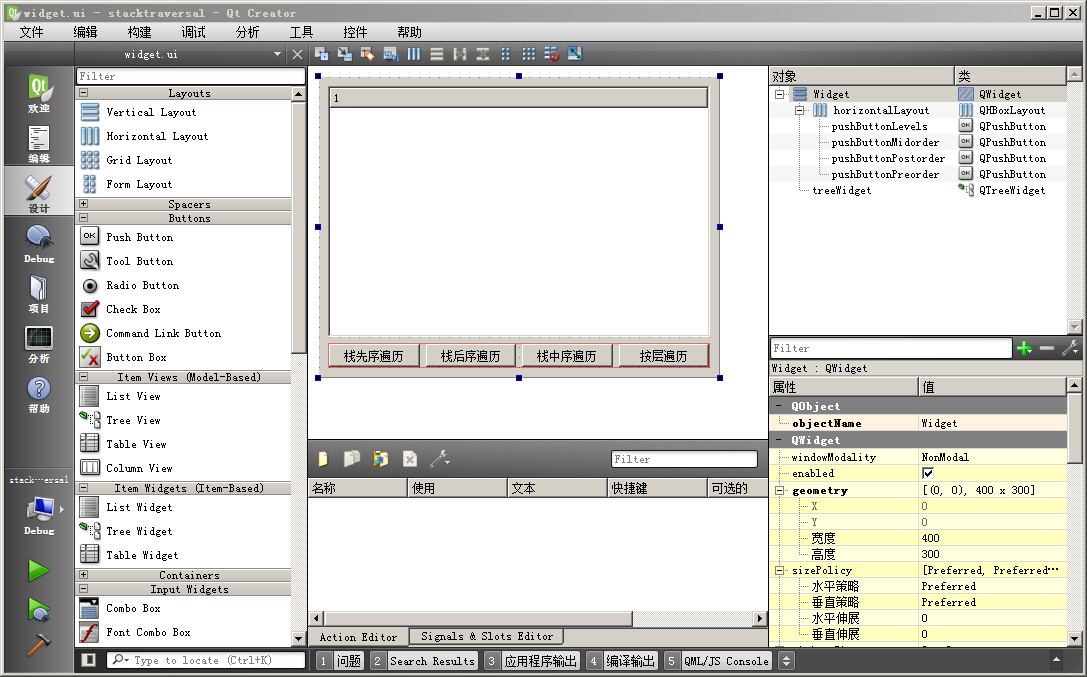 界面第一行是树形控件,默认对象名 treeWidget;
界面第一行是树形控件,默认对象名 treeWidget;
第二行是四个按钮:“栈先序遍历”pushButtonPreorder、“栈后序遍历”pushButtonPostorder、“栈中序遍历”pushButtonMidorder、“按层遍历”pushButtonLevels,第二行使用水平布局。
窗口整体使用垂直布局,窗口大小 400*300 。
布局设置好后,我们依次右击四个按钮,在右键菜单选择“转到槽...”,在弹出的对话框添加按钮点击信号对应的槽函数:
 添加四个槽函数后,我们保存界面文件,关闭界面文件。
添加四个槽函数后,我们保存界面文件,关闭界面文件。
下面开始编辑头文件 widget.h 的内容:
#ifndef WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <QTreeWidgetItem>//树形条目
#include <QTreeWidget> //树形控件
#include <QStack>//栈
#include <QQueue>//队列
namespace Ui {
class Widget;
}
class Widget : public QWidget
{
Q_OBJECT
public:
explicit Widget(QWidget *parent = 0);
~Widget();
private slots:
void on_pushButtonPreorder_clicked();
void on_pushButtonPostorder_clicked();
void on_pushButtonMidorder_clicked();
void on_pushButtonLevels_clicked();
private:
Ui::Widget *ui;
//先序遍历函数
void PreorderByStack(QTreeWidgetItem *curItem);
//后序遍历
void PostorderByStack(QTreeWidgetItem *curItem);
//中序遍历
void MidorderByStack(QTreeWidgetItem *curItem);
//按层遍历,队列实现
void LevelsByQueue(QTreeWidgetItem *curItem, int curLevel);
};
#endif // WIDGET_H
该文件添加了树形控件、树形条目、栈、队列的头文件包含。
窗口类的声明里,四个槽函数是用按钮的右键菜单添加的。
最后我们添加了四个遍历函数,分别按照先序、后序、中序和按层遍历树形结构。按层遍历的函数带有一个层级编号,该函数打印节点时,一块打印节点的层级编号。
下面我们分块编辑源文件 widget.cpp 的代码,首先是头文件包含、构造函数和析构函数:
#include "widget.h"
#include "ui_widget.h"
#include <QDebug>
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
ui->setupUi(this);
//树形控件只有一列数据
ui->treeWidget->setColumnCount(1);
//添加顶级节点
QTreeWidgetItem *itemA = new QTreeWidgetItem();
itemA->setText(0, "A");
ui->treeWidget->addTopLevelItem( itemA );
//A的两个子节点B、C
QTreeWidgetItem *itemB = new QTreeWidgetItem(itemA);
itemB->setText(0, "B");
QTreeWidgetItem *itemC = new QTreeWidgetItem(itemA);
itemC->setText(0, "C");
//B的两个子节点D、E
QTreeWidgetItem *itemD = new QTreeWidgetItem(itemB);
itemD->setText(0, "D");
QTreeWidgetItem *itemE = new QTreeWidgetItem(itemB);
itemE->setText(0, "E");
//C的两个子节点F、G
QTreeWidgetItem *itemF = new QTreeWidgetItem(itemC);
itemF->setText(0, "F");
QTreeWidgetItem *itemG = new QTreeWidgetItem(itemC);
itemG->setText(0, "G");
//展开所有
ui->treeWidget->expandAll();
}
Widget::~Widget()
{
delete ui;
}
构造函数先设置树形控件的列计数为 1;
为树形控件新建了顶级节点 "A";然后新建 "A" 的两个子节点 "B" 和 "C";
为 "B" 新建子节点 "D" 和 "E";为 "C" 新建子节点 "F" 和 "G" ;
构造函数末尾展开所有树形控件子节点,方便查看树。
下面编辑“栈先序遍历”按钮对应的槽函数:
void Widget::on_pushButtonPreorder_clicked()
{
//获取A节点
QTreeWidgetItem *itemA = ui->treeWidget->topLevelItem(0);
//进行先序遍历
qDebug()<<tr("先序遍历:");
PreorderByStack( itemA );
}
该槽函数获取 itemA 条目,然后调用下面的函数实现先序遍历:
//使用栈实现先序遍历
void Widget::PreorderByStack(QTreeWidgetItem *curItem)
{
//判断指针
if(NULL == curItem) return; //空指针不处理
//定义栈
QStack<QTreeWidgetItem *> stackItems;
//初始节点入栈
stackItems.push( curItem );
//用于遍历的条目变量
QTreeWidgetItem *itemTreversal = NULL;
while( ! stackItems.isEmpty() )
{
//栈顶的出栈
itemTreversal = stackItems.pop();
//先序是添加子节点之前部署工作代码,打印文本
qDebug()<<itemTreversal->text(0);
//子节点计数
int nChildCount = itemTreversal->childCount();
//如果是叶子就进行下一轮
if( nChildCount < 1 )
{
continue;
}
else//有子节点,子节点从右往左,倒序压栈
{
//倒序压栈,左边子节点处于栈顶,出栈时优先处理左边子节点
for(int i=nChildCount-1; i>=0; i--)
{
stackItems.push( itemTreversal->child(i) );
}
}
//下一轮循环
}//栈不空就一直循环处理
return; //结束
}
该函数先判断参数指针 curItem,如果为空就直接返回;curItem 不为空时,继续后面代码。
定义存储条目指针的栈 stackItems,将子树的根节点 curItem 压入栈中;
定义用于遍历树形结构的 itemTreversal 变量;
当栈非空时,一直循环处理:
取出栈顶元素,存到 itemTreversal ;
打印 itemTreversal 的文本,即工作代码;
获取 itemTreversal 子节点计数;
如果是叶子节点就跳过后面代码,继续下轮循环;
如果不是叶子,itemTreversal 存在子节点,那么将它的子节点从右到左压入栈中,这样等会出栈时,就可以先处理左子树;
当栈为空时,结束循环。
先序的特点是先打印父节点,后打印子节点,多个子节点打印时先左后右。我们将父节点出栈后打印,然后将其子节点压栈,当树形结构从上到下推进层次时,子孙节点就源源不断压入栈中;
压栈时右边子节点先入栈,左边子节点后入栈,这样出栈打印时顺序正好相反,出栈顺序是先左后右。
当栈被清空,没有新元素添加时,说明树节点遍历完成了。
下面编辑“栈后序遍历”按钮的槽函数:
void Widget::on_pushButtonPostorder_clicked()
{
//获取A节点
QTreeWidgetItem *itemA = ui->treeWidget->topLevelItem(0);
//后序遍历
qDebug()<<tr("后序遍历:");
PostorderByStack( itemA );
}
这个槽函数也非常简单,获取 itemA 之后调用下面函数进行后序遍历:
//用栈实现后序遍历
void Widget::PostorderByStack(QTreeWidgetItem *curItem)
{
//判断指针
if(NULL == curItem) return; //空指针不处理
//定义栈
QStack<QTreeWidgetItem *> stackItems;
//初始节点入栈
stackItems.push( curItem );
//遍历使用的条目变量
QTreeWidgetItem *itemTraversal = NULL;
QTreeWidgetItem *itemLast = NULL; //上次弹出的节点
//后序遍历时,第一步进行层次推进,父子节点先后进栈
//第二步出栈回归上层,子节点先出栈打印,父节点后出栈
while( ! stackItems.isEmpty() )
{
//后序遍历先打印所有子树,根节点要一直存在栈里,直到子树打印完才出栈
itemTraversal = stackItems.top();
//子节点计数
int nChildCount = itemTraversal->childCount();
//如果是叶子节点,推进层次截止
if( nChildCount < 1 )
{
//出栈打印
itemTraversal = stackItems.pop();
qDebug()<<itemTraversal->text(0);
//保存上次弹出节点,用于判断是推进层次还是回归顶层
itemLast = itemTraversal;
continue; //下一轮
}
//存在子节点时,可能是层次推进过程,也可能是回归上层的过程
//如果上次出栈打印的是当前节点的最右边儿子,那么子树打印过了,就是回归上层
//如果上次出栈打印的不是最右边儿子节点,那么需要进一步推进层次
if( itemTraversal->child( nChildCount-1 ) != itemLast )
{
//深入递推,那么将子节点压栈
//存在子节点,把子节点都入栈,从右向左压栈
for(int i=nChildCount-1; i>=0; i--)
{
//左子节点优先在栈顶,优先打印左边的
stackItems.push( itemTraversal->child(i) );
}
}
else//回归上层,那么将当前节点出栈并打印
{
//出栈打印
itemTraversal = stackItems.pop();
qDebug()<<itemTraversal->text(0);
//保存上次弹出节点
itemLast = itemTraversal;
}
//下一轮
}
return; //完成
}
该函数先检查参数指针 curItem ,如果为空就返回不处理,如果非空继续后面代码。
定义保存树形节点指针的栈 stackItems;
将初始的根节点 curItem 压入栈中;
定义遍历树形结构的变量 itemTraversal,以及保存上一次出栈元素变量 itemLast;
当栈内非空时一直循环处理:
获取栈顶元素存到 itemTraversal,但是栈顶元素不出栈,因为子树的根节点要等子孙遍历完才能出栈;
获取 itemTraversal 的子节点数 nChildCount;
判断 itemTraversal 如果为叶子节点,那么进入工作代码:
将栈顶元素出栈,打印节点文本,将出栈的元素存到 itemLast 供下轮循环使用,然后 continue进入下轮循环;
接着是对有子节点的 itemTraversal 进行判断,如果上一轮的 itemLast 不是 itemTraversal 最右儿子节点,那么进入推进层次的代码:
将 itemTraversal 所有子节点,按照从右到左顺序压入栈中,然后自动进入下轮循环;
如果上一轮的 itemLast 正好是 itemTraversal 最右儿子节点,那么进入回归上层的代码:
将栈顶元素出栈,打印文本,将出栈的元素存到 itemLast 供下轮循环使用,然后自动进入下轮循环。
当栈清空,没有新元素加入时,循环结束,完成遍历。
上述处理过程比较复杂的是对栈顶节点有子节点时的判断,后序遍历会先推进到叶子层次,先打印下层节点,然后逐步返回到上层。遇到栈顶节点有子节点时,有可能是推进层次,也可能是回归上层,判断条件就是当儿子们都打印完成,那么说明是返回上层,儿子节点当中最右边的儿子最后打印,所以根据 itemLast 是否为 itemTraversal 最右边儿子节点来判断当前是在推进层次还是返回上层。
下面来编辑“栈中序遍历”的槽函数代码:
void Widget::on_pushButtonMidorder_clicked()
{
//获取A节点
QTreeWidgetItem *itemA = ui->treeWidget->topLevelItem(0);
//中序遍历
qDebug()<<tr("中序遍历:");
MidorderByStack( itemA );
}
该槽函数获取 itemA 之后,调用下面函数实现中序遍历:
//用栈实现中序遍历
void Widget::MidorderByStack(QTreeWidgetItem *curItem)
{
//判断指针
if(NULL == curItem) return; //空指针不处理
//定义栈
QStack<QTreeWidgetItem *> stackItems;
//初始节点入栈
stackItems.push(curItem);
//遍历的节点遍历
QTreeWidgetItem *itemTraversal = NULL;
//循环
while( ! stackItems.isEmpty() )
{
//把所有层的最左节点压栈
while( stackItems.top()->childCount() >= 1 )
{
stackItems.push( stackItems.top()->child(0) );
}
//总是从最左边节点开始出栈
while( ! stackItems.isEmpty() )
{
//出栈并打印
itemTraversal = stackItems.pop();
qDebug()<<itemTraversal->text( 0 );
//子节点计数
int nChildCount = itemTraversal->childCount();
//如果存在右边的节点
if( nChildCount >= 2 )
{
//右边的子节点都入栈,压栈时从右往左,出栈时就是从左到右
for(int i=nChildCount-1; i>=1; i--)
{
stackItems.push( itemTraversal->child(i) );
}
//该节点还存在右边的子树,跳出内层循环,对右边子树按照外层循环操作
break;
}
}
//下一轮外层循环
}
return; //完成
}
该槽函数先判断参数指针 curItem,如果为空就返回,如果非空继续后面代码。
定义保存树形条目的栈 stackItems;
将参数的子树根条目 curItem 压入栈中;
定义遍历树形结构的变量 itemTraversal;
中序遍历的实现比较复杂,用了两层遍历循环,第一层当栈非空时一直处理:
内层第一段循环,在子树里面一直向最底层左子节点推进层次并压栈,到子树最底层最左边叶子节点为止;
内层第二段循环功能如下:
将当前栈顶节点出栈,打印节点文本;
获取当前节点的子节点计数;
如果不存在右边子节点,就继续下一轮内层第二段循环;
如果存在右边的子节点(右子树):
循环将右边的子节点从右向左压入栈中;
存在右边子节点很可能代表右边的子树,所以要对右边子树进行递推,要跳转到外层循环处理。
外层循环在栈清空后,没有节点了就结束。
内层的两段循环各有分工:第一段一直推进左边节点层次到叶子为止;第二段将栈顶节点出栈打印,并将可能的右子树根节点压入栈,凡是有右子树的情况都跳到外层循环处理,否则继续内层第二段循环。
下面编辑“按层遍历”按钮的槽函数:
void Widget::on_pushButtonLevels_clicked()
{
//获取A节点
QTreeWidgetItem *itemA = ui->treeWidget->topLevelItem(0);
//按层遍历,显示节点层号
qDebug()<<tr("按层遍历,显示节点层号:");
LevelsByQueue( itemA, 0 );
}
该槽函数获取 itemA 节点,然后调用下面函数实现按层遍历:
//用队列实现按层遍历
void Widget::LevelsByQueue(QTreeWidgetItem *curItem, int curLevel)
{
//判断指针
if(NULL == curItem) return; //空指针不处理
//定义两个队列,一个保存节点,另一个保存节点的层级
QQueue<QTreeWidgetItem *> queueItems;
QQueue<int> queueLevels;
//初始节点入队
queueItems.enqueue( curItem );
queueLevels.enqueue( curLevel );
//遍历的变量
QTreeWidgetItem *itemTraversal = NULL;
int nLevel = -1;
//循环按层遍历
while( ! queueItems.isEmpty() )
{
itemTraversal = queueItems.dequeue();
nLevel = queueLevels.dequeue();
//打印当前节点和层级
qDebug()<<itemTraversal->text(0)<<" , "<<nLevel;
//获取子节点计数
int nChildCount = itemTraversal->childCount();
//分别入队
for(int i=0; i<nChildCount; i++)
{
queueItems.enqueue( itemTraversal->child( i ) );
queueLevels.enqueue( nLevel + 1 );
}
//下一轮
}
return; //完成
}
该函数有两个参数,第一个参数是当前子树的根 curItem,第二个是该根节点的层级编号。
函数先判断指针 curItem ,如果为空就直接返回,如果非空继续后面代码。
定义保存树形条目指针的队列 queueItems;
定义保存条目对应层级编号的队列 queueLevels,这两个队列始终保持同步操作。
将节点 curItem 加入到队列 queueItems,同时将它的层级加入到队列 queueLevels;
定义遍历树形结构的变量 itemTraversal ,以及它的层级编号 nLevel;
下面当队列非空时一直处理:
将队列 queueItems 头部元素出队,存到 itemTraversal,并将 queueLevels 队列同样出队,层级存到 nLevel;
打印节点文本和它的层级;
获取子节点计数 nChildCount;
然后将每个子节点全都加入到队列 queueItems,并将子节点层级编号加入到队列 queueLevels。
当队列清空时,循环结束,按层遍历完成。
代码讲解到这,下面构建运行示例,测试先序遍历打印如下:
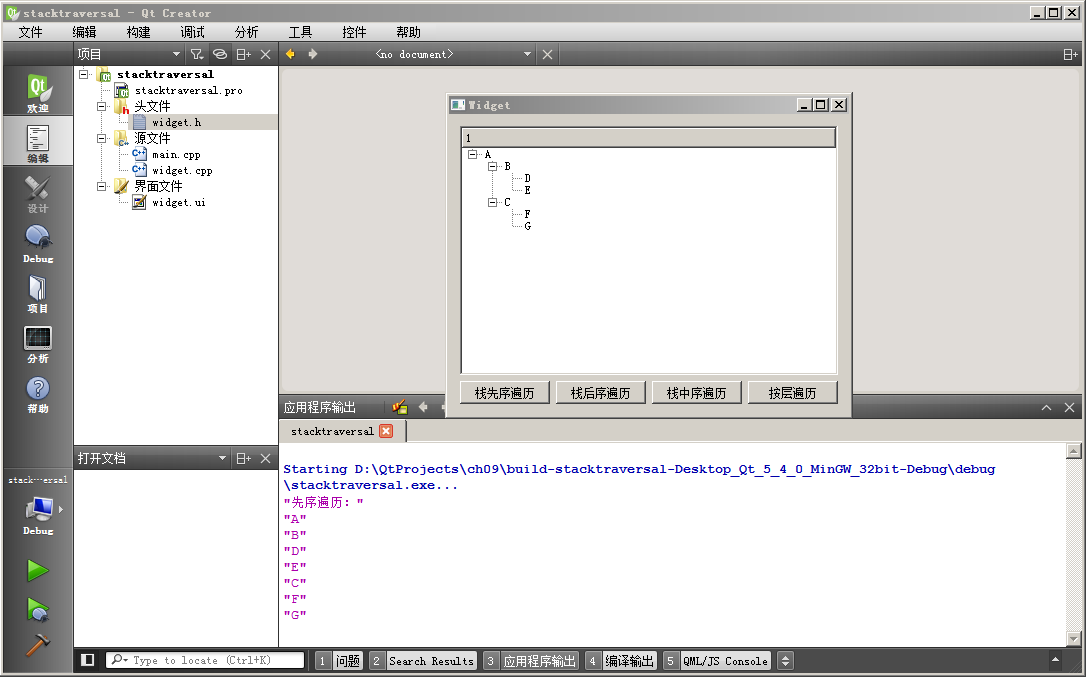 其他功能读者自行测试。在树形节点不多的情况下,递归函数遍历和栈遍历都可以使用。
其他功能读者自行测试。在树形节点不多的情况下,递归函数遍历和栈遍历都可以使用。
当树形节点数量达到十万量级以后,通常必须用栈遍历,因为递归函数的层次太多,很可能导致程序的函数执行栈溢出,程序就会崩溃。QStack 在堆上分配空间,而不依赖函数执行栈,就不容易出现溢出的情况。函数执行栈一般只有 1MB ~ 2MB,而堆空间可以分配 * GB 。
9.2.3 顺序容器对比
五种顺序容器其实按照基类来说,只有三类:QList(含派生类 QQueue)、QLinkedList、QVector(含派生类 QStack),概括来说,它们的应用场景如下:
① 在大多数情况下,QList 都是非常优秀的选择。QList 基于序号的访问机制比链表 QLinkedList 访问效率要高, 通常情况 QList 的访问速度优于 QVector,因为 QList 专门优化过内存存储方式,并且 QList 的代码编写也很简洁。
② 如果需要使用链式的数据结构,希望随机插入、随机删除总是常量时间,那么应该使用 QLinkedList。
③ 如果希望元素在内存中连续相邻存储,就是使用封装好的数组,那么 QVector 是适合的选择。
④ Qt 另外提供了低级别的可变长度数组 QVarLengthArray, 比 QVector 函数少一些,QVarLengthArray 不会初始化C++基本类型的元素,而 QVector 总是对元素做初始化。通常情况下,连续空间数组的场景建议优先使用 QVector 。
QList、QLinkedList、QVector 各种操作的算法复杂度不一样,用于描述算法复杂度的标记为 O(*) ,常见的列举如下:
① 常量时间,记为 O(1) 。即某操作的时间与容器中的元素多少无关,链表的插入操作就是常量时间。
② 对数时间,记为 O(log n)。在容器上的某个操作耗费时间与元素个数的对数成比例关系,对于排序好的数组,使用二分查找 qBinaryFind() 就是对数时间。
③ 线性时间,记为 O(n)。在容器上的某个操作时间直接与元素个数成比例关系,向量的插入操作就是线性时间。
④ 线性对数时间,记为 O(n log n)。在容器上的某个操作时间与(元素个数×元素个数的对数) 成比例关系。快速排序和堆排序的平均算法复杂度就是 O(n log n) 。
⑤ 二次方时间,记为 O(n2) 。在容器上的某个操作的时间与 元素个数的二次方 成比例关系。冒泡排序算法就是二次方时间。
我们对 QLinkedList、QList、QVector 常见操作的算法复杂度列举如下:
| 容器类型 |
索引查找 |
随机插入 |
头部添加 |
尾部追加 |
| QLinkedList |
O(n) |
O(1) |
O(1) |
O(1) |
| QList / QQueue |
O(1) |
O(n) |
Amort. O(1) |
Amort. O(1) |
| QVector / QStack |
O(1) |
O(n) |
O(n) |
Amort. O(1) |
表格中 Amort. 是 amortized behavior 的缩写,即均摊行为。以 Amort. O(1) 为例,如果程序仅执行一次操作,那么有可能是 O(n) 时间,但是如果执行很多次该操作,那么很多次平均分摊下来,平均的时间是 O(1) 。
从表格上的算法复杂度来看,QList 的操作效率比较高,并且支持数组下标访问,QLinkedList 虽然增删元素效率高,但是访问元素的效率比较低,并且不支持数组下标访问。大多数情况下都建议使用 QList ,Qt 很多的类函数涉及到序列存储时,都是优先使用 QList ,比如获取本地主机 IP 地址列表 QNetworkInterface::allAddresses() 、获取声卡设备列表QAudioDeviceInfo::availableDevices(QAudio::Mode mode) 等等。
下面我们设计一个示例,用于测试 QLinkedList、QList、QVector 常见操作耗费的时间。
Qt 提供了耗费时间计时器类 QElapsedTimer ,该类的使用举例如下:
QElapsedTimer timer;
timer.start();
slowOperation1();
qDebug() << "The slow operation took" << timer.elapsed() << "milliseconds";
定义耗费计时器对象 timer,调用 timer.start() 开始计时,然后执行某操作,操作结束后调用计时函数 timer.elapsed() ,就可以获知某操作花费的时间。QElapsedTimer 的计时函数主要有两个:
qint64 elapsed() const //计算耗费的毫秒时间,milliseconds
qint64 nsecsElapsed() const //计算耗费的纳秒时间,nanoseconds
我们的示例里面用纳秒计时。由于纳秒计数的数值位数多,我们可以采用 QLocale 类实现数字转字符串时的三位数逗号分隔功能,使用英文本地化,将数字转为字符串时就会自动每三个数字加一个逗号分隔符,比如:
QLocale alocale = QLocale(QLocale::English, QLocale::UnitedStates);
qDebug()<<alocale.toString( 1234567 );
打印效果就是: "1,234,567" ,这样方便查看数字的位数进行多个时间数据的对比。
打开 QtCreator,新建一个 Qt Widgets Application 项目,在新建项目的向导里填写:
①项目名称 sequentialtest,创建路径 D:\QtProjects\ch09,点击下一步;
②套件选择里面选择全部套件,点击下一步;
③基类选择 QWidget,点击下一步;
④项目管理不修改,点击完成。
我们打开 widget.ui 界面文件,按照下图拖入控件:
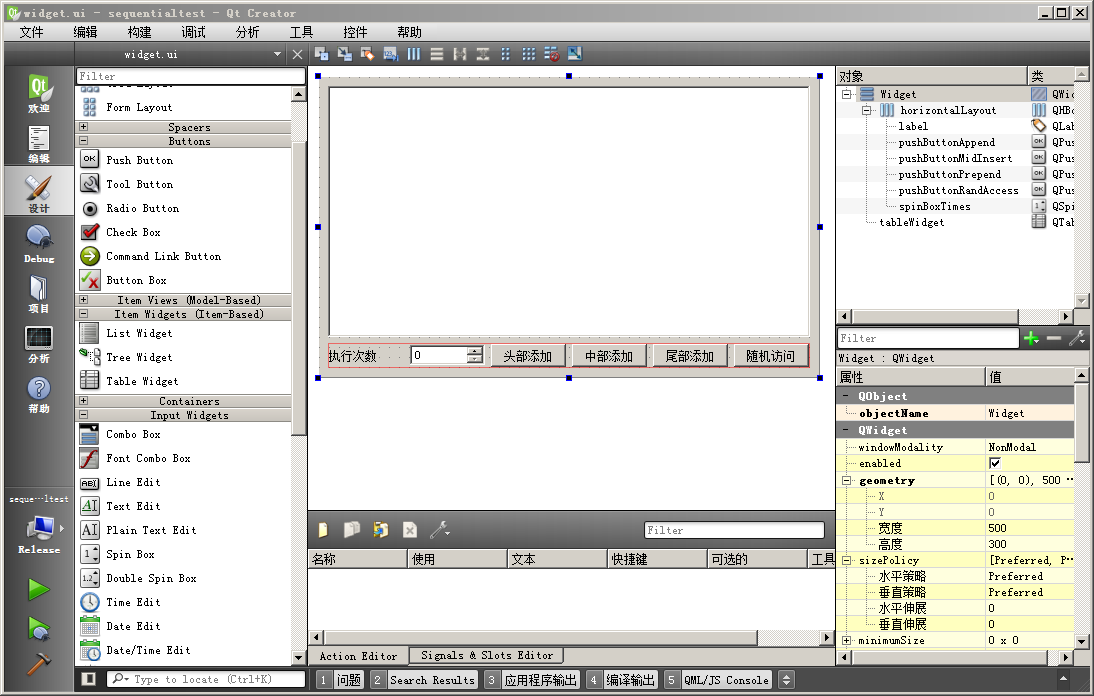 界面第一行是表格控件,默认对象名 tableWidget;
界面第一行是表格控件,默认对象名 tableWidget;
第二行是标签“执行次数”、旋钮编辑框 spinBoxTimes,
按钮“头部添加”pushButtonPrepend、“中部添加”pushButtonMidInsert、
“尾部添加”pushButtonAppend、“随机访问”pushButtonRandAccess,第二行使用水平布局。
窗口整体使用垂直布局,窗口大小 500*300。
我们依次右击 4 个按钮,在右键菜单选择“转到槽...”,弹出如下对话框:
选择信号 clicked() ,点击OK按钮,为 4 个按钮都添加对应的槽函数。
槽函数添加完成后,我们保存界面文件,关闭界面文件,然后对头文件 widget.h 进行编辑:
#ifndef WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <QLinkedList>//链表
#include <QList> //列表
#include <QVector>//向量
#include <QElapsedTimer> //耗费计时
#include <QLocale> //本地化类,用于打印逗号分隔的数字
namespace Ui {
class Widget;
}
class Widget : public QWidget
{
Q_OBJECT
public:
explicit Widget(QWidget *parent = 0);
~Widget();
private slots:
void on_pushButtonPrepend_clicked();
void on_pushButtonMidInsert_clicked();
void on_pushButtonAppend_clicked();
void on_pushButtonRandAccess_clicked();
private:
Ui::Widget *ui;
//链表
QLinkedList<int> m_linkdList;
//列表
QList<int> m_list;
//向量
QVector<int> m_vector;
//耗费计时器
QElapsedTimer m_calcTimer;
//本地化对象,用于打印逗号分隔的数字
QLocale m_locale;
};
#endif // WIDGET_H
该文件添加了需要测试的链表、列表、向量模板类的头文件包含,以及测试耗时类、本地化类的头文件包含。
类声明里面,4 个槽函数都是右键菜单添加的;
然后定义了 3 个测试对象 m_linkdList、m_list、m_vector;
定义了测试耗时类的对象 m_calcTimer,以及用于生成英文风格数字字符串的 m_locale 对象。
下面分段编辑源文件 widget.cpp 的内容,首先是头文件包含、构造函数和析构函数:
#include "widget.h"
#include "ui_widget.h"
#include <QDebug>
#include <QMessageBox>
#include <QTableWidgetItem>//表格控件条目
#include <QTableWidget>//表格控件
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
ui->setupUi(this);
//设置标题栏
setWindowTitle( tr("顺序容器操作耗时测试,时间单位:纳秒") );
//设置表格列计数
ui->tableWidget->setColumnCount( 4 );
//设置表头
QStringList header;
header<<tr("操作名称")<<tr("QLinkedList")<<tr("QList")<<tr("QVector");
ui->tableWidget->setHorizontalHeaderLabels( header );
//各列均匀拉伸
ui->tableWidget->horizontalHeader()->setSectionResizeMode( QHeaderView::Stretch );
//设置旋钮编辑框
ui->spinBoxTimes->setSuffix( tr(" 万") );//次数的单位是万
ui->spinBoxTimes->setRange( 1, 21*10000 );//测试次数范围从1万到21亿,int上限是 21 亿多
//设置英语本地化,每3个数字使用逗号分隔
m_locale = QLocale(QLocale::English, QLocale::UnitedStates);
qDebug()<<m_locale.toString( 1234567 );
}
Widget::~Widget()
{
delete ui;
}
开头添加了打印调试信息、消息框、表格条目和表格控件的头文件包含。
构造函数里先修改窗口标题栏,提示本程序测试顺序容器的操作耗时,时间单位纳秒;
设置表格的列数为 4,定义表头的字符串列表 header,将四列表头文本存到该字符串列表,然后设置给表格的水平表头。
设置水平表头的分段尺寸调整模式为 QHeaderView::Stretch,就可以让表格自动均匀拉伸各列,并占满水平空间。
设置旋钮编辑框的后缀为 " 万" ,测试以 1 万次为步进,然后设置旋钮编辑框的数字范围从 1 到 210000,即 1 万到 21 亿,因为 int 的上限是 21 亿多,所以设置了上限为 21 亿。
构造函数末尾设置 m_locale 为英文本地化,然后打印 m_locale.toString( 1234567 ) 生成的字符串,简单测试一下英文本地化的效果。
下面编辑“头部添加”按钮的槽函数代码:
//测试头部添加的耗时
void Widget::on_pushButtonPrepend_clicked()
{
//获取测试次数
int nTimes = ui->spinBoxTimes->value() * 10000;
//表格控件添加新行
int nNewRow = ui->tableWidget->rowCount(); //新增行的序号
ui->tableWidget->setRowCount( nNewRow + 1 );
//设置第 0 列文本
QString strText = tr("头部添加 %1 万次").arg( ui->spinBoxTimes->value() );
QTableWidgetItem *itemNew = new QTableWidgetItem( strText );
ui->tableWidget->setItem(nNewRow, 0, itemNew);
//链表测试,先清空旧的内容
m_linkdList.clear();
qint64 nsUsed = 0; //统计纳秒数
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
m_linkdList.prepend( i ); //头部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 1, itemNew );
//列表测试,先清空旧的内容
m_list.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间,避免频繁分配空间和复制元素
m_list.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_list.prepend( i ); //头部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 2, itemNew );
//向量测试,先清空旧的
m_vector.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间
m_vector.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_vector.prepend( i ); //头部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 3, itemNew );
//滚动到最下面新建行
ui->tableWidget->scrollToBottom();
}
该函数先获取测试次数,并将旋钮编辑框的数值乘以 10000,就是实际的操作次数 nTimes。
获取旧的表格行计数存到 nNewRow,然后为表格添加一个新行,新行序号就是 nNewRow。
设置文本 strText 为 "头部添加 %1 万次" ,%1 就是旋钮编辑框的数值;
根据字符串 strText 新建表格条目,设置给表格的 nNewRow 行 0 列。
然后准备链表的测试,将链表 m_linkdList 旧内容清空,定义存储纳秒数的变量 nsUsed;
调用 m_calcTimer.start() 开始计时;
用循环添加 nTimes 次数据到链表头部;
循环结束后获取耗时纳秒数,存到 nsUsed;
调用 m_locale.toString( nsUsed ) 把纳秒数转为英文风格的字符串,每三位数字用逗号分隔;
根据该字符串新建表格条目,设置到表格的 nNewRow 行 1 列。
接下来是列表 m_list 头部添加测试,代码和链表测试非常类似,只是最后的表格条目设置为 nNewRow 行 2 列。
向量 m_vector 的测试代码与上面的链表、列表类似,将新表格条目设置为 nNewRow 行 3 列。
最后将表格自动滚动到最底下,显示新增的行。
下面编辑“中部添加”按钮的槽函数代码:
//测试中部添加的耗时
void Widget::on_pushButtonMidInsert_clicked()
{
int nTimes = ui->spinBoxTimes->value() * 10000;
//表格控件添加新行
int nNewRow = ui->tableWidget->rowCount(); //新增行的序号
ui->tableWidget->setRowCount( nNewRow + 1 );
//设置第 0 列文本
QString strText = tr("中部添加 %1 万次").arg( ui->spinBoxTimes->value() );
QTableWidgetItem *itemNew = new QTableWidgetItem( strText );
ui->tableWidget->setItem(nNewRow, 0, itemNew);
//链表测试,先清空旧的内容
m_linkdList.clear();
qint64 nsUsed = 0; //统计纳秒数
QLinkedList<int>::iterator it; //迭代器
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
int nMid = m_linkdList.count() / 2;
//用迭代器访问,链表如果知道指向元素的迭代器,那么增删效率高
//如果不知道中间元素迭代器,那么迭代器遍历的时间比较长
it = m_linkdList.begin();
for(int j=0; j<nMid; j++)
{
it++;
}
//中部添加
m_linkdList.insert(it, i);
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 1, itemNew );
//列表测试,先清空旧的
m_list.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间,避免频繁分配空间和复制元素
m_list.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_list.insert( m_list.count()/2, i );
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 2, itemNew );
//向量测试,先清空旧的
m_vector.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间
m_vector.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_vector.insert( m_vector.count()/2, i );
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 3, itemNew );
//滚动到最下面新建行
ui->tableWidget->scrollToBottom();
}
该函数首先获取测试次数 nTimes;
为表格添加新的行,新行序号 nNewRow;
设置新行 0 列的文本为 "中部添加 %1 万次" ,%1 是旋钮编辑框的数值。
然后准备链表的中部添加测试,将旧的链表内容清空,定义纳秒数变量 nsUsed;
与之前“头部添加”按钮代码不同的是,这里定义了迭代器 it,用于访问链表中间元素。
调用 m_calcTimer.start() 开始测试链表;
外层循环进行 nTimes 次:
计算中部的序号 nMid;
获取链表开始的迭代器,用内层循环遍历迭代器 nMid-1 次,这时迭代器正好指向序号为 nMid 的元素;
在中部元素之前插入新元素,数值为 i。
外层循环结束后获取耗时存到 nsUsed;
然后调用 m_locale.toString( nsUsed ) 设置英文风格的数值字符串,
根据 strText 新建表格条目设置到 nNewRow 行 1 列。
后面是列表 m_list 、向量 m_vector 的测试代码,比链表简单一些,因为它们中间插入元素不需要迭代器,
计算了中部序号 count()/2 后直接插入新元素即可。然后设置文本,新建表格条目,设置到新行的后面两列。
函数最后把表格滚动到底部,显示新增的行。
下面编辑“尾部添加”的槽函数代码:
//测试尾部添加的耗时
void Widget::on_pushButtonAppend_clicked()
{
//获取测试次数
int nTimes = ui->spinBoxTimes->value() * 10000;
//表格控件添加新行
int nNewRow = ui->tableWidget->rowCount(); //新增行的序号
ui->tableWidget->setRowCount( nNewRow + 1 );
//设置第 0 列文本
QString strText = tr("尾部添加 %1 万次").arg( ui->spinBoxTimes->value() );
QTableWidgetItem *itemNew = new QTableWidgetItem( strText );
ui->tableWidget->setItem(nNewRow, 0, itemNew);
//链表测试,先清空旧的
m_linkdList.clear();
qint64 nsUsed = 0; //统计纳秒数
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
m_linkdList.append( i );//尾部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 1, itemNew );
//列表测试,先清空旧的
m_list.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间
m_list.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_list.append( i );//尾部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 2, itemNew );
//向量测试,先清空旧的
m_vector.clear();
//开始计时
m_calcTimer.start();
//提前保留元素空间
m_vector.reserve( nTimes );
for(int i=0; i<nTimes; i++)
{
m_vector.append( i );//尾部添加
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 3, itemNew );
//滚动到最下面新建行
ui->tableWidget->scrollToBottom();
}
“尾部添加”按钮的槽函数与“头部添加”按钮的槽函数内容几乎一样,仅仅是将容器的 prepend() 函数换成了 append() 函数,这里就不赘述了。
最后是“随机访问”按钮的槽函数代码:
void Widget::on_pushButtonRandAccess_clicked()
{
//获取测试次数
int nTimes = ui->spinBoxTimes->value() * 10000;
//查看元素数量是否有 nTimes 个
if( m_list.count() < nTimes )
{
QMessageBox::warning(this, tr("随机访问"), tr("请先进行任意其他项测试为顺序容器添加元素。"));
return;
}
//每个容器已经有了 nTimes 个元素
//表格控件添加新行
int nNewRow = ui->tableWidget->rowCount(); //新增行的序号
ui->tableWidget->setRowCount( nNewRow + 1 );
//设置第 0 列文本
QString strText = tr("随机访问 %1 万次").arg( ui->spinBoxTimes->value() );
QTableWidgetItem *itemNew = new QTableWidgetItem( strText );
ui->tableWidget->setItem(nNewRow, 0, itemNew);
//计时变量和随机序号变量
qint64 nsUsed = 0; //纳秒计时
int nIndex = 0; //随机序号
//链表测试,随机访问
int nAllCount = m_linkdList.count(); //元素数量
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
//生成新的随机序号
nIndex = ( nIndex + qrand() ) % nAllCount;
//迭代器
QLinkedList<int>::iterator it = m_linkdList.begin();
for(int j=0; j<nIndex; j++) //只能用迭代器查找元素
{
it++;
}
(*it) += i; //获取元素值并加上 i
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 1, itemNew );
//列表随机访问测试
nAllCount = m_list.count(); //元素的数量
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
//生成新的随机序号
nIndex = ( nIndex + qrand() ) % nAllCount;
m_list[ nIndex ] += i; //将元素值加 i
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 2, itemNew );
//向量随机访问测试
nAllCount = m_vector.count();
//开始计时
m_calcTimer.start();
for(int i=0; i<nTimes; i++)
{
//生成新的随机序号
nIndex = ( nIndex + qrand() ) % nAllCount;
m_vector[ nIndex ] += i; //将元素值加 i
}
nsUsed = m_calcTimer.nsecsElapsed();//耗时
//设置文本并新建表格条目
strText = m_locale.toString( nsUsed );
itemNew = new QTableWidgetItem(strText);
ui->tableWidget->setItem( nNewRow, 3, itemNew );
//滚动到最下面新建行
ui->tableWidget->scrollToBottom();
}
该函数首先获取测试次数 nTimes;
然后对列表的元素个数进行判断,如果不够 nTimes 个,弹出消息框提示用户使用其他测试按钮为容器添加元素,然后返回;
如果列表元素的数量够 nTimes 个,继续后面的随机访问测试代码。
我们为表格新增一行,新的行号为 nNewRow;
设置文本 strText 为 "随机访问 %1 万次" ,%1 是旋钮编辑框的数值;
根据文本 strText 新建表格条目,设置为表格的 nNewRow 行 0 列。
定义纳秒数变量 nsUsed 和随机访问使用的序号变量 nIndex;
获取链表的元素总数 nAllCount,用于后面的模运算,限定随机序号范围,保证不越界。
调用 m_calcTimer.start() 开始计时;
外层循环执行 nTimes 次数:
设置新的随机序号 nIndex,计算方式是旧的序号加新随机数,然后模 nAllCount ;
定义迭代器,获取列表的开始迭代器;
用内层循环遍历迭代器 nIndex -1 次,这样迭代器 it 正好指向序号为 nIndex 的元素;
将 nIndex 序号的元素数值加 i 。
外层循环结束后获取耗时纳秒数 nsUsed;
然后设置文本 strText,新建表格条目,设置为表格的 nNewRow 行 1 列内容。
后面列表、向量的测试代码相对简单,随机序号生成方法是一样的,因为列表和向量可以用数组下标形式读写元素,所以用起来比链表方便多了。
函数最后将表格滚动到最底下,显示新增的行。
代码讲解到这,我们构建运行该示例,测试一下效果:
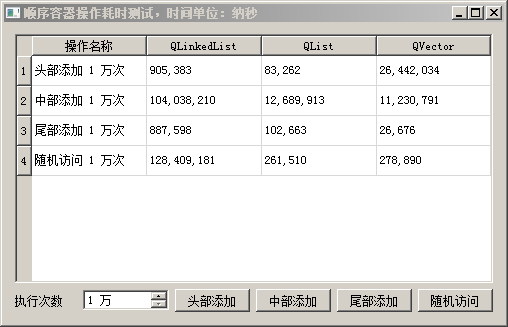 在四项测试中,列表 QList 的操作时间都是比较短的,操作执行效率高。
在四项测试中,列表 QList 的操作时间都是比较短的,操作执行效率高。
随机访问链表的时间很长,因为需要不停地遍历迭代器,查找元素迭代器位置;另外,理论上说链表的头部、中部、尾部以及其他任意位置的元素插入都是一样的时间,测试时由于没有提前获知链表中部元素的迭代器,所以费了很长时间去找中部元素迭代器,大部分时间用于查询迭代器,而不是用于添加元素。
向量的尾部添加时间最快,而头部添加需要大量复制后面元素,为头部元素腾出空间,所以头部添加时间较长。
本节的内容到这,我们下节开始学习关联容器。


